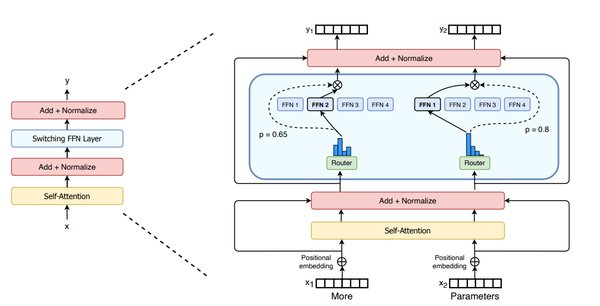
引言
随着人工智能技术的快速发展,大规模语言模型(LLM)的规模与复杂性日益增加。Mixture-of-Experts(MoE)模型作为一种高效的计算架构,通过仅激活部分专家(Experts)来处理特定任务,显著降低了计算成本。然而,MoE模型的分布式训练与推理面临着一个关键挑战:专家之间的高效通信。DeepSeek推出的DeepEP正是为解决这一问题而生。

DeepEP的核心特性
DeepEP是一款专为MoE模型设计的高性能通信库,其核心特性包括:
1. 高效通信协议:DeepEP优化了专家之间的通信协议,支持高吞吐量的训练和推理预填充操作。
2. 低精度计算支持:DeepEP支持FP8数据传输,显著减少了通信开销,同时保持了计算精度。
3. 深度优化场景:针对NVLink(节点内)和RDMA(节点间)的非对称带宽转发场景,DeepEP进行了深度优化,确保了高效的通信性能。

DeepEP的技术创新
DeepEP在技术实现上采用了多项创新:
– 混合精度计算:在模型的前向传播中,DeepEP使用8位浮点数(FP8)进行计算,同时通过定制化的GEMM例程确保精度。
– 通信与计算重叠:通过将计算与通信任务重叠,DeepEP最大限度地降低了通信延迟。例如,在H800 GPU上,专门分配了20个流式多处理器用于GPU间通信。
– 负载均衡优化:DeepEP通过动态调整专家的物理位置(每10分钟一次)和引入辅助负载均衡损失函数,进一步优化了通信效率。
DeepEP的应用场景
DeepEP的开放为MoE模型的训练与推理带来了显著提升,适用于以下场景:
– 大规模分布式训练:在多个GPU节点上训练MoE模型时,DeepEP能够显著减少通信瓶颈,提高训练效率。
– 高性能推理:在实时推理任务中,DeepEP的低延迟通信协议确保了快速响应。
– 低精度计算环境:在资源受限的环境中,DeepEP的FP8支持使得模型能够在保持性能的同时降低计算成本。
总结
DeepEP的推出标志着MoE模型通信优化领域的一个重要里程碑。通过高效的通信协议、低精度计算支持以及针对特定场景的深度优化,DeepEP为大规模语言模型的训练与推理提供了强有力的技术支持。随着DeepEP的开放,更多开发者将能够利用这一工具,进一步推动人工智能技术的发展与创新。







