引言
随着大模型在自然语言处理、计算机视觉等领域的广泛应用,如何提升推理效率、降低资源消耗成为业界关注的焦点。量化技术作为一种有效的优化手段,能够显著减少模型的计算复杂度和内存占用。本文将深入探讨从FP8到INT4的无缝量化技术在大模型推理中的应用,分析其核心原理、实现方法及实际效果。
量化技术的核心原理
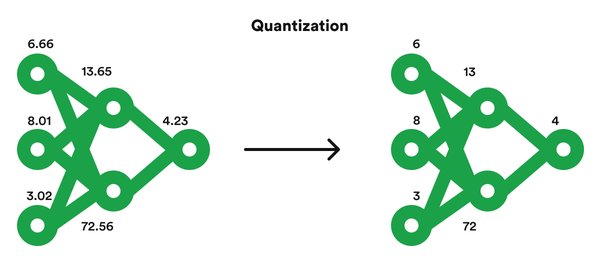
量化技术通过将模型的权重和激活从高位宽表示转换为低位宽表示,从而减少计算和内存成本。具体来说,量化过程包括以下几个步骤:
-
权重量化:将FP16张量量化为低位整型张量,如INT8、INT4等。
-
激活量化:在推理过程中,对激活值进行量化,以减少计算复杂度。
-
去量化:在计算过程中,将低位宽表示恢复为高位宽表示,以保持计算精度。

无缝量化技术的实现方法
无缝量化技术的核心在于如何在量化过程中保持模型的精度,同时实现计算效率的最大化。以下是几种常见的无缝量化方法:
-
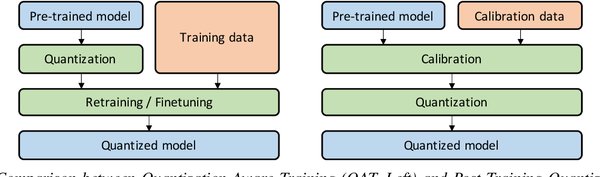
Post-Training Quantization (PTQ):在模型训练完成后进行量化,无需重新训练。这种方法适用于大规模模型的快速部署。
-
Quantization-Aware Training (QAT):在模型训练过程中引入量化操作,使模型能够适应量化带来的误差。这种方法能够提高量化模型的精度。
-
混合精度量化:根据模型的不同部分,采用不同的量化精度。例如,对关键部分采用较高精度,对非关键部分采用较低精度。
实际应用中的效果
在实际应用中,无缝量化技术能够显著提升大模型的推理效率。以下是几个典型应用场景:
-
FP8量化:在A100显卡上,FP8量化能够将70B参数模型的推理速度提升至每秒60个token,较传统方案提升4.5倍。
-
INT4量化:在资源受限的场景中,INT4量化能够将模型的内存占用减少至原来的1/4,同时保持较高的推理精度。
-
动态批处理:通过自适应计算图分割技术,将模型分解为可并行化的微算子,进一步提升计算密度。
技术架构与优化
无缝量化技术的成功离不开先进的技术架构和优化策略。以下是几种关键的优化技术:
-
混合精度调度器:根据计算需求动态调整量化精度,以实现计算效率的最大化。
-
稀疏注意力核:通过稀疏化注意力机制,减少计算复杂度,提升推理速度。
-
显存虚拟化技术:通过显存虚拟化技术,有效管理显存资源,提高资源利用率。
开源生态与开发者支持
随着无缝量化技术的普及,开源生态也在不断完善。目前,Hugging Face模型库已集成无缝量化技术,开发者可以通过配置文件完成主流大模型的部署优化。此外,随着对MoE架构的专项支持,该工具链正成为企业级AI落地的核心基建,为实时交互、内容生成等场景提供工业化级解决方案。
结论
从FP8到INT4的无缝量化技术在大模型推理中展现出了巨大的潜力。通过量化技术,开发者能够在保持模型精度的同时,显著提升推理效率,降低资源消耗。随着技术的不断进步和开源生态的完善,无缝量化技术将成为大模型推理优化的核心手段,为AI应用的普及和落地提供强有力的支持。







