近年来,大模型(LLM)在自然语言处理、代码生成等任务中展现出强大的能力,但其庞大的计算和内存需求对资源受限场景的部署提出了巨大挑战。微软研究院开源的DeepSpeed-FastGen工具通过创新的动态序列批处理技术和异构内存管理系统,显著提升了大模型推理效率,降低了硬件成本,为大模型的实际应用铺平了道路。

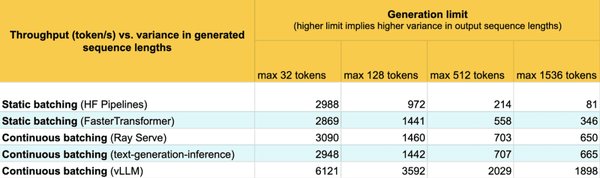
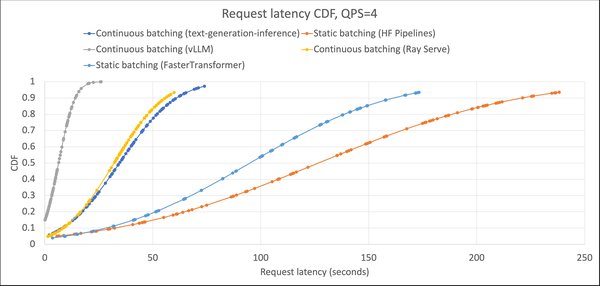
动态序列批处理技术:提升系统吞吐量
DeepSpeed-FastGen的核心创新之一是动态序列批处理技术。传统的批处理方式在处理不同长度的请求时,容易出现资源利用率低下的问题。DeepSpeed-FastGen通过以下方式优化了这一过程:
-
迭代级批处理:将不同请求的计算分解为多个迭代,并在每个迭代中动态批处理新请求,充分利用空闲资源。
-
Split-and-Fuse方法:将长预填充请求拆分为多个短请求,与解码请求批处理在一起,平衡工作负载,减少尾部延迟。
这些技术显著提高了系统吞吐量,使得单节点NVIDIA A100 GPU能够同时处理120个并发会话,极大地提升了资源利用率。
异构内存管理系统:降低硬件成本
DeepSpeed-FastGen的另一个亮点是其异构内存管理系统。该系统通过以下方式优化内存使用:
-
分页KV缓存:将KV缓存以分页方式存储,减少内存碎片,提高内存利用率。
-
动态内存分配:根据请求的生成长度动态分配内存,避免静态分配导致的资源浪费。
这些优化使得DeepSpeed-FastGen能够在有限的硬件资源下高效运行130B参数的模型,降低了硬件成本,为大模型的广泛部署提供了可能。
实际应用场景:广泛的应用潜力
DeepSpeed-FastGen在实际应用中展现了广泛的应用潜力,特别是在以下领域:
-
电商:通过高效的推理服务,实时生成个性化推荐和商品描述,提升用户体验。
-
医疗:加速医疗文本的生成和分析,支持临床决策和病历管理。
-
金融:快速生成金融报告和风险分析,提高决策效率和准确性。
开源生态:快速成长的社区支持
DeepSpeed-FastGen的开源生态快速成长,HuggingFace已集成该工具的适配器,进一步推动了其在开发者社区中的普及。开源社区的支持不仅加速了工具的迭代优化,还为其在不同应用场景中的落地提供了丰富的实践案例。
未来展望:持续优化与扩展
尽管DeepSpeed-FastGen已经取得了显著的成果,但其在以下方面仍有进一步优化的空间:
-
调度策略:开发更智能的调度策略,进一步优化系统吞吐量和响应时间。
-
边缘部署:探索在资源受限的边缘设备上的部署方案,扩大其应用范围。
-
安全性:研究效率与安全性之间的平衡,确保大模型推理的安全性和可靠性。
DeepSpeed-FastGen通过创新的动态序列批处理技术和异构内存管理系统,显著提升了大模型推理效率,降低了硬件成本,为大模型的实际应用开辟了新的可能性。随着开源生态的快速成长和持续优化,DeepSpeed-FastGen将在更多领域展现其广泛的应用潜力。




