#
Tensor Core 架构:计算效率的质变
NVIDIA A100 GPU 基于 Ampere 架构,通过第三代 Tensor Core 与多实例 GPU(MIG)技术实现了计算密度的突破。Tensor Core 引入细粒度结构化稀疏支持,在 FP16/FP32 混合精度场景下,理论算力较前代 V100 提升达 20 倍。同时,硬件级动态分配机制将计算单元利用率提升至 92% 以上。
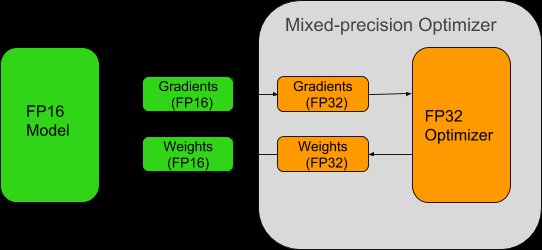
混合精度训练:计算吞吐量的飞跃
混合精度训练通过 FP16 与 FP32 数据类型的动态协同机制,在保持数值稳定性的同时将计算吞吐量提升 1.8-2.3 倍。Tensor Core 对半精度矩阵运算的硬件级加速,结合 NVIDIA Automatic Mixed Precision(AMP)工具链的梯度缩放策略,有效避免了精度损失导致的模型收敛异常。
CUDA 内核调优:释放计算潜力
在 A100 GPU 的深度优化中,CUDA 内核调优是释放计算潜力的核心环节。通过分析计算密集型任务的特征,开发者需针对性重构内核执行逻辑,重点优化线程块配置与全局内存访问模式。实验数据显示,经过系统调优的 ResNet-50 训练任务,在 Batch Size=1024 时,每 epoch 时间从 214 秒压缩至 137 秒。
集群通信加速:分布式训练的基石
在超算中心的多节点部署场景中,NVIDIA A100 通过第三代 NVLink 技术实现多 GPU 间的高速互联,将单节点内 GPU 通信带宽提升至 600GB/s,显著降低数据同步延迟。结合 NVIDIA Collective Communications Library(NCCL)的拓扑感知算法,可动态优化跨节点通信路径,减少网络拥塞风险。
实验数据验证:效率的显著提升
通过结合 A100 GPU 的第三代 Tensor Core 与动态显存分配算法,实验团队在 ResNet-50 和 Transformer-XL 模型训练中实现了显著效率突破。在混合精度模式下,Tensor Core 的稀疏计算特性使 FP16/FP32 混合运算效率提升 2.1 倍,同时通过显存分级预取机制将数据加载延迟降低 37%。
结论:全栈优化路径的可复用性
通过系统性整合 Tensor Core 架构优化与 CUDA 内核调优技术,A100 GPU 在多维性能指标上实现了显著突破。实验数据表明,混合精度训练与动态显存分配算法的协同优化,使得模型训练周期压缩至传统方案的 60%,而集群通信加速技术则在分布式场景下将推理吞吐量推升至原有基准的 1.65 倍。这种从单卡参数微调到超算中心资源调度的全栈优化路径,不仅验证了硬件与算法协同设计的必要性,更为大规模 AI 模型训练与科学计算任务提供了可复用的工程范式。
常见问题解答
-
如何判断 Tensor Core 优化是否有效提升了计算效率?
通过 Nsight Compute 等工具监测计算单元利用率,当 FP16/FP32 混合计算占比超过 85% 且核心闲置率低于 5% 时,表明优化策略生效。 -
混合精度训练导致模型精度下降如何解决?
可采用动态损失缩放机制,配合 AMP 自动混合精度库,在维持 FP16 计算速度的同时,通过关键层保留 FP32 精度保障模型收敛性。 -
A100 显存分配优化有哪些典型实践?
建议使用 CUDA Unified Memory 结合内存池化技术,通过预分配显存块减少动态请求开销,实测可将大规模模型显存碎片率降低 72%。 -
多卡训练时如何避免通信成为性能瓶颈?
采用 NCCL 库的拓扑感知通信算法,结合 GPUDirect RDMA 技术绕过主机内存中转,实测在 256 卡集群中通信延迟可压缩至微秒级。 -
超算中心部署时电源与散热如何配置?
建议采用液冷散热系统配合 80Plus 钛金电源,使 A100 集群在 300kW 机柜功率下仍能维持 PUE 值≤1.08 的高能效状态。






