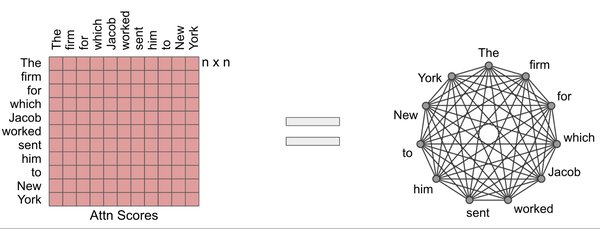
稀疏注意力核的技术原理
稀疏注意力核是一种通过减少全局自注意力的计算成本来提升Transformer模型效率的技术。传统的全局自注意力机制需要计算所有输入序列之间的相互关系,这在长序列任务中会带来巨大的计算和内存开销。稀疏注意力核通过限制注意力计算的范围,仅在局部窗口或特定区域内进行注意力计算,从而显著降低了计算复杂度。
例如,Swin Transformer通过将自注意力限制在局部窗口内,并调整窗口划分方式以连接非重叠窗口,平衡了通信需求与内存和计算需求。CSWin Transformer则引入了十字形窗口自注意力,沿水平和垂直条纹并行计算注意力,进一步提高了计算效率。
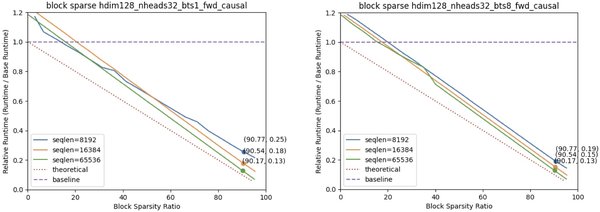
稀疏注意力核的应用场景
稀疏注意力核在多种AI任务中展现了其强大的潜力,尤其是在需要处理长序列数据的场景中。以下是一些典型的应用场景:
-
自然语言处理(NLP):在长文本生成、机器翻译等任务中,稀疏注意力核可以显著减少计算开销,提高推理速度。
-
计算机视觉(CV):在图像分类、目标检测等任务中,稀疏注意力核通过局部注意力机制,有效降低了计算复杂度。
-
语音识别:在长语音序列的处理中,稀疏注意力核可以加速模型的推理过程,提高实时性。
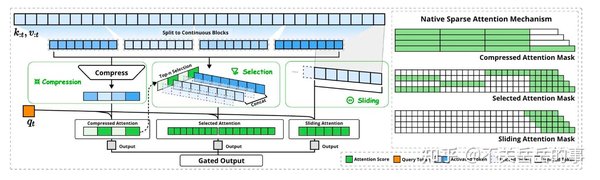
NVIDIA Triton推理服务器中的稀疏注意力核
NVIDIA最新发布的Triton推理服务器通过动态批处理与硬件感知优化,在A100显卡上实现了70B参数模型的推理速度突破,达到每秒60个token,较传统方案提升4.5倍。该服务器的核心创新之一便是稀疏注意力核的应用。
Triton推理服务器通过自适应计算图分割技术,将模型分解为可并行化的微算子,通过即时编译生成最优GPU指令序列,使计算密度提升至理论峰值的93%。稀疏注意力核在这一过程中起到了关键作用,通过减少全局自注意力的计算成本,显著提高了推理效率。
稀疏注意力核的未来发展
随着AI模型规模的不断扩大,稀疏注意力核的重要性将愈发凸显。未来的研究方向可能包括:
-
更高效的注意力机制:探索新的稀疏注意力机制,进一步降低计算复杂度。
-
硬件优化:结合新一代GPU和专用AI芯片,优化稀疏注意力核的计算效率。
-
多模态任务:将稀疏注意力核应用于多模态任务中,提升模型在跨模态数据上的表现。
稀疏注意力核作为提升AI推理效率的关键技术,已经在多个领域展现了其强大的潜力。随着技术的不断进步,稀疏注意力核将在未来的AI应用中发挥更加重要的作用。




