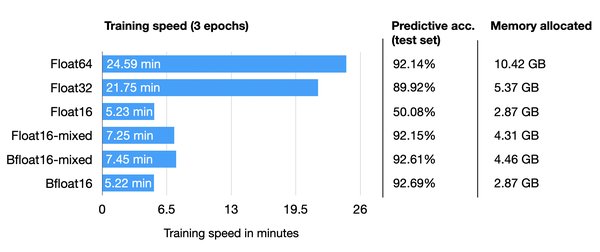
混合精度调度器的背景与意义
在AI大模型的训练和推理中,算力需求和资源消耗是核心挑战。传统的高精度计算(如FP32)虽然能保证模型稳定性,但计算成本和内存占用极高。混合精度调度器的出现,通过结合高精度和低精度计算(如FP16、FP8),在保证模型性能的同时显著降低了资源消耗。这种技术不仅提升了计算效率,还为更大规模、更复杂的AI应用提供了可能。

混合精度调度器的技术原理
混合精度调度器的核心在于动态调整计算精度,以优化计算密度和内存利用率。其技术架构通常包括以下关键组件:
-
精度动态调整:根据任务需求,自动选择FP32、FP16或FP8等精度进行计算。
-
计算图分割:将模型分解为可并行化的微算子,通过即时编译生成最优GPU指令序列。
-
硬件感知优化:结合GPU架构特性,最大化利用计算资源,如NVIDIA的Tensor Core和PTX优化技术。
DeepSeek的PTX优化与混合精度实践
DeepSeek在混合精度调度器的应用中,通过PTX优化技术实现了显著的性能提升。其创新点包括:
-
FP8混合精度训练:在超大规模模型上验证了FP8计算和存储技术的有效性,显著提升了训练速度并降低了GPU内存占用。
-
DualPipe算法:通过高效的流水线并行处理,减少流水线停滞,降低通信开销。
-
PTX指令级优化:利用PTX语言直接控制GPU资源,优化线程调度、内存管理和寄存器使用,最大化计算性能。
NVIDIA Triton推理服务器的创新
NVIDIA Triton推理服务器通过混合精度调度器和其他优化技术,在A100显卡上实现了70B参数模型的推理速度突破,达到每秒60个token。其核心创新包括:
-
自适应计算图分割:将模型分解为可并行化的微算子,通过即时编译生成最优GPU指令序列。
-
稀疏注意力核:优化注意力机制的计算效率,减少冗余计算。
-
显存虚拟化技术:动态分配显存资源,提高利用率。
混合精度调度器的应用场景与未来展望
混合精度调度器的应用场景广泛,涵盖AI训练、推理以及边缘计算等领域。未来发展方向包括:
-
训练-推理一体化:支持模型在推理中持续学习,如推荐系统和自动驾驶。
-
绿色AI:通过模型剪枝和稀疏训练降低能耗,推动可持续发展。
-
硬件生态扩展:支持更多专用AI芯片和异构计算架构,如TPU和ASIC。
总结
混合精度调度器作为AI计算性能优化的新引擎,正在深刻改变AI模型的训练和推理方式。通过结合DeepSeek的PTX优化技术和NVIDIA Triton推理服务器的创新,混合精度调度器不仅提升了计算效率,还为AI技术的普及和应用拓展提供了强大支持。未来,随着技术的进一步发展,混合精度调度器将在AI领域发挥更加重要的作用,推动AI计算走向高效化、普惠化和绿色化。





