
DeepEP:MoE模型通信的革命性工具
DeepSeek近期宣布向公众开放DeepEP,这是一款专为Mixture-of-Experts(MoE)模型设计的高性能通信库。MoE模型通过仅激活部分专家来处理每个token,从而大幅提升计算效率。然而,当这些专家分布在多个GPU上时,通信效率成为关键瓶颈。DeepEP通过优化NVLink和RDMA的通信模式,解决了这一难题,为现代高性能计算提供了强大的支持。
NVLink在DeepEP中的核心作用
NVLink是NVIDIA开发的一种高速互连技术,能够显著提升GPU之间的数据传输效率。DeepEP充分利用了NVLink的优势,实现了以下优化:
– 高吞吐量通信:通过NVLink的带宽优势,DeepEP在MoE模型的训练和推理预填充阶段实现了高效的数据传输。
– 低延迟解码:针对推理解码阶段,DeepEP设计了专用低延迟内核,进一步提升了性能。
– FP8数据支持:DeepEP支持FP8低精度数据传输,减少带宽需求,同时保持计算精度。
低精度计算与通信优化的结合
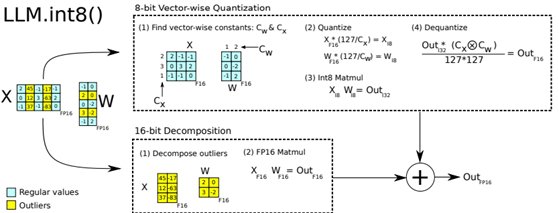
DeepEP的另一大亮点是其对低精度计算的深度支持。以下是其关键技术点:
– FP8浮点数:在MoE模型的前向传播中,DeepEP大量使用8位浮点数(5E2M格式),显著降低了计算和通信开销。
– 混合精度算术:DeepEP结合了16位(BF16)和12位(E5M6)浮点数,进一步优化了计算效率。
– 通信与计算重叠:通过将通信与计算任务重叠,DeepEP最大限度地减少了等待时间,提升了整体性能。
DeepEP的实际应用与性能提升
DeepEP的设计不仅限于理论优化,其在实际应用中也表现出色:
– 负载均衡:DeepEP通过动态调整专家的分布位置,避免了某些GPU的过载问题,同时通过辅助负载均衡损失函数优化了训练效率。
– 多场景支持:无论是NVLink还是RDMA,DeepEP都能在不同硬件环境下提供稳定的高性能表现。
总结
DeepEP的开放标志着MoE模型通信技术的一次重大突破。通过结合NVLink的高带宽优势和低精度计算技术,DeepEP为分布式AI训练和推理提供了高效、可靠的解决方案。随着AI模型的规模不断扩大,类似DeepEP的通信优化工具将成为推动技术进步的关键力量。




