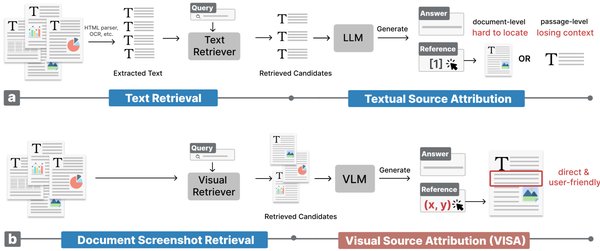
RAG引擎的核心功能与应用场景
RAG(Retrieval-Augmented Generation)引擎是一种结合了检索和生成技术的AI工具,广泛应用于文档解析、智能客服、自动化报表生成等领域。其核心功能包括深度文档解析、混合检索优化、工作流编排和多模态支持。
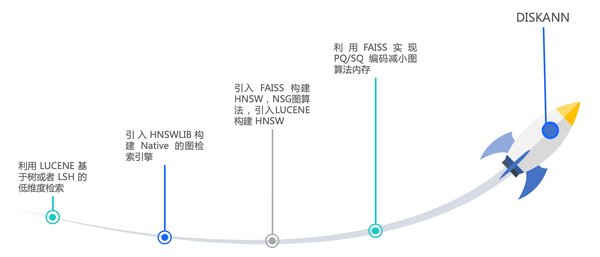
深度文档解析
RAG引擎能够处理PDF、扫描件、表格等复杂格式文档,支持OCR、表格识别、代码块提取等功能。例如,RAGFlow在处理包含扫描合同和Excel表格的压缩包时,不仅准确提取了文字和表格结构,还能在后续问答中引用具体条款。
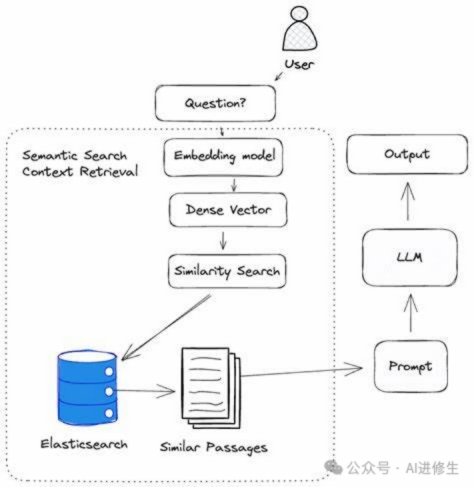
混合检索优化
RAG引擎通过结合Elasticsearch和自研算法实现多路召回+重排序,显著提升答案准确性。例如,RAGFlow在处理非结构化数据时,解析精度比传统RAG工具高出约30%。
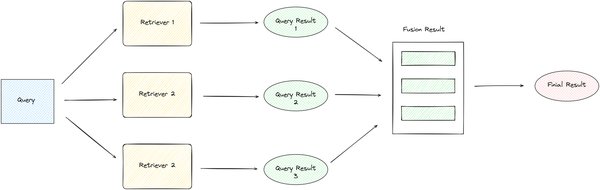
工作流编排
RAG引擎支持自定义解析→检索→生成流程,例如设定“若置信度低于阈值则触发人工审核”。这种灵活性使得RAG引擎能够适应各种复杂的业务需求。
多模态支持
RAG引擎的实验性功能已支持音频文件转文字并生成摘要。这种多模态支持能力使得RAG引擎在处理复杂数据时更加得心应手。

Dify与RAGFlow的对比
核心能力
-
RAGFlow:文档解析精度高,答案可溯源,适合法律合同审查、医疗报告分析等场景。
-
Dify:工作流编排灵活,支持多模型协作,适合智能客服、自动化报表生成等场景。
使用场景
-
RAGFlow:在处理批量扫描版财务报表时,表格识别准确率比Dify高出约30%。
-
Dify:在快速搭建集成GPT-4和Stable Diffusion的多模态应用时,可视化流程设计器更高效。
开发门槛
-
RAGFlow:需调整解析参数和检索策略,适合有开发经验的用户。
-
Dify:可视化拖拽,适合无代码基础用户。
部署实践与优化建议
部署实践
以Ubuntu 22.04为例,部署RAGFlow的步骤如下:
-
环境准备:安装Docker及Compose,确保版本≥24.0.0和v2.26.1。
-
获取项目并启动:通过Git获取项目并启动容器,首次启动需下载约9GB的镜像,建议使用国内镜像加速。
-
模型配置:在Web界面中填写本地LLM地址,选择Embedding模型,测试连接状态。
优化建议
-
硬件资源:8核CPU+32GB内存可支撑20并发问答。
-
知识库分片:按业务类型拆分知识库,提升检索速度。
-
安全加固:通过Nginx添加HTTPS和IP白名单,避免内网暴露风险。
总结
RAG引擎在文档解析、智能客服等领域展现了强大的应用潜力。Dify和RAGFlow各有优劣,开发者应根据具体需求选择合适的工具。通过合理的部署和优化,RAG引擎能够为企业级文档智能处理提供强有力的支持。





.png)
