在人工智能领域,大模型的研发一直是技术竞争的焦点。然而,高昂的训练成本和计算资源需求往往成为许多企业难以跨越的门槛。中国人工智能初创企业深度求索公司(DeepSeek)凭借其DeepSeek-V3大模型,以低成本、高性能的创新路径,成功打破了这一局面,赢得了全球开源社区的广泛赞誉。

低成本与高性能的完美结合
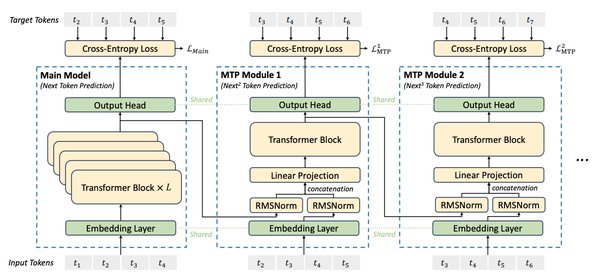
DeepSeek-V3大模型的核心竞争力在于其卓越的性能和极低的训练成本。与传统的大模型相比,DeepSeek-V3通过一系列创新技术,显著降低了训练过程中的计算资源消耗。例如,其采用的混合专家模型(MoE)和多头潜在注意力机制(MLA),不仅提高了模型的泛化能力,还大幅减少了内存占用和计算量。
此外,深度求索公司还开源了FlashMLA和DeepEP等AI基础设施项目,这些项目旨在从芯片中获取最佳性能,实现经济高效的模型训练和推理任务。通过这些技术,DeepSeek-V3能够在性能较弱的芯片上实现高效的模型训练,进一步降低了成本。


开源社区的广泛赞誉
深度求索公司的开源举措赢得了全球开发者社区的广泛支持。美国旧金山AI行业解决方案提供商龙鳞工业公司的首席技术官斯蒂芬·皮门特尔在社交平台上表示,深度求索公司的开源项目“有力驳斥了外界常说的‘他们在训练程序上撒谎’的论调”。开源开发者们也对深度求索公司的技术表示了高度赞赏,认为其“再次拓展了AI基础设施的极限”。


与全球AI巨头的竞争
尽管预算有限,DeepSeek-V3在性能上仍能与美国AI巨头的最出色模型相媲美。例如,OpenAI的GPT-4和Anthropic的PaLM-2等模型在文本生成、语义理解和计算推理等方面表现出色,而DeepSeek-V3在这些领域同样展现了强大的竞争力。特别是在数学问题解决和代码生成补全等任务中,DeepSeek-V3的表现尤为突出。
技术创新的核心
DeepSeek-V3的成功离不开其多项技术创新:
-
混合专家模型(MoE):通过将模型划分为多个专家子模型,动态选择最适合的专家处理不同任务,提高了模型的效率和鲁棒性。
-
多头潜在注意力机制(MLA):通过压缩键和值为低秩潜在向量,减少了内存占用和计算量,同时保留了多头注意力机制的优点。
-
稀疏注意力机制:仅关注最相关的token,降低了计算开销,提高了模型在处理大规模数据集时的效率。
未来展望
随着人工智能技术的不断发展,DeepSeek-V3大模型有望在更多领域实现应用突破。深度求索公司将继续优化其训练和优化过程,进一步提高模型的计算效率和性能。同时,开源社区的广泛支持也将为DeepSeek-V3的进一步发展提供强大的动力。
结语
DeepSeek-V3大模型的出现,不仅标志着中国在AI技术领域的重大突破,也为全球AI行业提供了低成本、高性能的创新路径。通过开源和技术创新,深度求索公司正在重新定义AI大模型的研发和应用规则,为全球AI技术的发展注入了新的活力。