近日,中国人工智能初创企业深度求索(DeepSeek)宣布开源其全新代码库DeepEP,这是全球首个专注于混合专家模型(MoE)训练与推理的开源通信库。这一重大举措不仅驳斥了外界对其虚报成本的指控,还为AI行业注入了新的活力,赢得了开源社区的广泛赞誉。
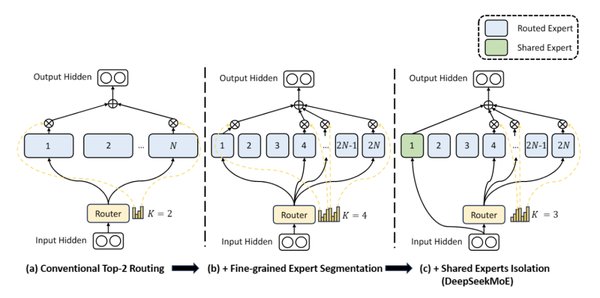

混合专家模型的高效训练与推理
混合专家模型(MoE)是一种将多个专家模型组合在一起的架构,能够在处理复杂任务时实现更高的效率和性能。然而,MoE模型的训练与推理对通信能力的要求极高,尤其是在大规模数据和复杂模型的场景下。
深度求索开源的DeepEP正是为了解决这一问题而设计的。其核心优势在于高效的通信能力,支持节点内和节点间的NVLink及RDMA通信,极大提升了数据传输的效率。此外,DeepEP还提供了预填充的高吞吐量内核和低延迟内核,分别针对训练和推理阶段进行了优化,确保了模型训练的高效性和推理解码的实时性。
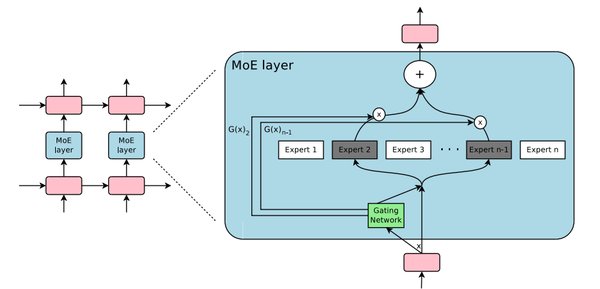

低成本、高性能的技术创新
尽管深度求索的预算远低于其规模更大的竞争对手,但其通过一系列创新技术实现了成本效益的培训。例如,DeepEP对原生FP8调度的支持和灵活的GPU资源控制功能,进一步提升了模型训练的效率和资源利用率。
深度求索此前发布的开源AI模型V3和R1,被认为可以与美国AI巨头的最出色模型相媲美。这些成就不仅展示了深度求索的技术实力,也证明了其在有限预算下实现高性能的能力。


开源社区的积极反响
深度求索的开源项目赢得了开源社区的广泛认可。美国旧金山AI行业解决方案提供商龙鳞工业公司的首席技术官斯蒂芬·皮门特尔在社交平台上表示,深度求索的技术开源“有力驳斥了外界常说的‘他们在训练程序上撒谎’的论调”。
开源开发者对深度求索的项目纷纷表示赞赏,称其“正再次拓展AI基础设施的极限”。这种积极的反馈不仅提升了深度求索的行业地位,也为AI技术的进一步发展提供了新的动力。
未来展望
深度求索的开源项目标志着AI模型训练进入了一个全新的高效时代。对于广大开发者和研究者来说,这是一次难得的机遇,能够借助这一强大工具,加速AI模型的开发与应用。
随着AI技术的不断发展,混合专家模型的应用场景将更加广泛。深度求索的开源项目不仅为行业提供了新的技术解决方案,也为未来的AI创新奠定了坚实的基础。
深度求索的成功再次证明,技术创新和开源精神是推动AI行业发展的关键力量。我们期待更多企业能够加入到这一行列中,共同推动AI技术的进步与应用。




