
引言
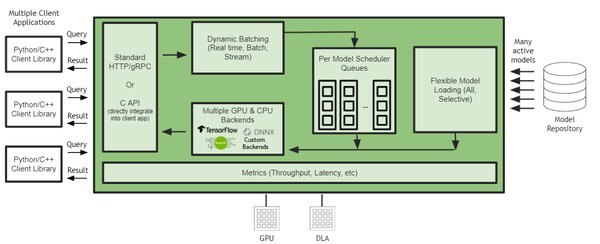
随着AI模型规模的不断扩大,传统的推理方法已无法满足高效计算的需求。NVIDIA最新发布的Triton推理服务器通过自适应计算图分割技术,在A100显卡上实现了70B参数模型的推理速度突破,达到每秒60个token,较传统方案提升4.5倍。这一技术的核心在于将模型分解为可并行化的微算子,通过即时编译生成最优GPU指令序列,使计算密度提升至理论峰值的93%。
自适应计算图分割技术的核心原理
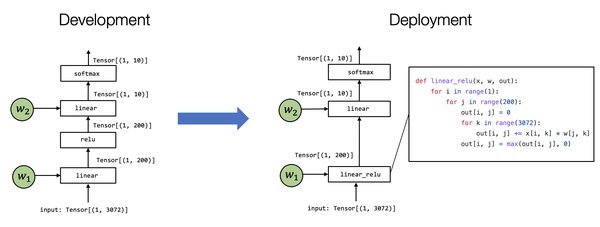
自适应计算图分割技术是一种将复杂计算图分解为多个可并行化微算子的方法。该技术通过即时编译生成最优GPU指令序列,显著提升了计算密度和推理速度。其核心优化包括:
-
混合精度调度器:动态调整计算精度,平衡计算速度和精度。
-
稀疏注意力核:优化注意力机制的计算,减少冗余计算。
-
显存虚拟化技术:高效利用显存资源,支持更大规模的模型推理。
应用场景与优势
自适应计算图分割技术在多个AI应用场景中展现出显著优势:
-
实时交互:在聊天机器人、虚拟助手等实时交互场景中,低延迟的推理能力至关重要。
-
内容生成:在文本生成、图像生成等任务中,高效的推理速度可以大幅提升用户体验。
-
混合专家模型(MoE):该技术对MoE架构的专项支持,使得大规模模型的推理更加高效。
技术架构的三重优化
NVIDIA Triton推理服务器的技术架构围绕三重优化展开:
-
混合精度调度器:通过动态调整计算精度,实现计算速度和精度的最佳平衡。
-
稀疏注意力核:优化注意力机制的计算,减少冗余计算,提升计算效率。
-
显存虚拟化技术:高效利用显存资源,支持更大规模的模型推理。
开源生态与开发者支持
Triton推理服务器已集成Hugging Face模型库,开发者可通过配置文件完成主流大模型的部署优化。这一开源生态为开发者提供了极大的便利,使得自适应计算图分割技术能够广泛应用于各类AI项目中。
未来展望
随着AI技术的不断发展,自适应计算图分割技术将继续推动AI推理性能的提升。未来,该技术有望在更多应用场景中发挥重要作用,成为企业级AI落地的核心基建,为实时交互、内容生成等场景提供工业化级解决方案。
结论
自适应计算图分割技术通过将复杂计算图分解为可并行化的微算子,显著提升了AI推理性能。NVIDIA Triton推理服务器的成功应用,展示了该技术在实时交互、内容生成等场景中的巨大潜力。随着技术的不断优化和开源生态的完善,自适应计算图分割技术将继续引领AI推理性能的革命性突破。








