

视觉语言模型(VLM)的科研与版权争议
近年来,视觉语言模型(VLM)在科研领域的应用引发了广泛的版权争议。科研论文被出版商以高价出售给科技公司用于训练AI模型,而论文作者却未获得任何收益。华盛顿大学的AI研究员Lucy Lu Wang指出,任何在线可读内容都可能已被用于训练大型语言模型(LLM),这进一步加剧了版权问题的复杂性。
与此同时,北大和港大的学者利用arXiv中的论文图文构建了高质量的多模态数据集,显著提升了VLM的数学推理能力。这一进展不仅展示了VLM在科研中的潜力,也揭示了科研、版权和AI之间的复杂关系。

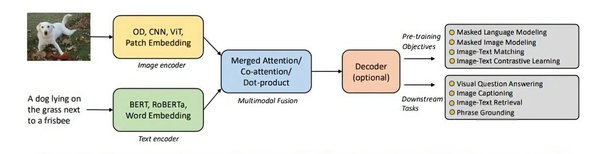
多模态信息检索系统的构建
在商业应用领域,VLM正在推动多模态信息检索系统的发展。NVIDIA NIM微服务通过集成先进的视觉语言模型(如llama-3.2-90b-vision-instruct)和大语言模型(如mistral-small-24B-instruct),构建了一个能够处理文本、图像和表格的复杂查询系统。
该系统的主要优势包括:
-
增强上下文理解:通过长上下文建模,VLM能够处理冗长而复杂的视觉文档,避免传统模型的分块问题。
-
结构化输出:NVIDIA NIM原生支持生成结构化输出,确保响应的一致性和可靠性。
-
无缝集成外部工具:通过LangChain和LangGraph,系统能够动态选择和使用外部工具,提高数据提取和解释的精度。
这种多模态信息检索系统在企业应用中具有广泛潜力,尤其是在处理大型非结构化数据集时,能够提供快速、准确的响应。
具身智能的突破:Helix VLA一体化模型
在具身智能领域,Figure AI发布的Helix模型标志着VLM技术的又一重大突破。Helix是全球首个视觉-语言-动作(VLA)一体化模型,能够对人形机器人上半身进行高频率、连续控制,并支持多机器人协作完成复杂任务。
Helix的核心技术包括:
-
双系统架构:系统1(S1)负责实时控制的“快反应”模块,系统2(S2)负责语义理解的“慢思考”模块。
-
端到端训练:从原始像素和文本指令直接映射到连续动作,确保训练与部署的一致性。
-
低数据依赖与本地化部署:仅需500小时训练数据,即可在嵌入式低功耗GPU上运行,大幅降低使用门槛。
Helix的发布不仅解决了传统VLM模型在推理速度和动作精度上的问题,还为具身智能的商业化铺平了道路。
未来展望:VLM的广泛应用与挑战
随着VLM技术的不断发展,其在科研、商业和具身智能领域的应用将更加广泛。然而,挑战依然存在:
-
版权问题:如何平衡科研论文的版权保护与AI模型的训练需求,仍需进一步探讨。
-
可扩展性与成本:处理大规模数据集时,如何优化资源利用率并降低成本,是企业面临的主要问题。
-
技术整合:如何将VLM与其他AI技术无缝整合,以实现更复杂的应用场景,是未来研究的重要方向。
VLM正在推动AI技术的边界,为科研、商业和具身智能领域带来前所未有的机遇与挑战。








