在人工智能领域,大型语言模型(LLM)的部署和应用日益广泛,但随之而来的风险也不容忽视。Anthropic的Alignment Science团队最近发布了一项新研究,旨在预测这些模型在部署后可能出现的罕见行为风险。这项研究不仅为LLM开发者提供了新的工具,也为确保模型的安全性和可靠性提供了科学依据。
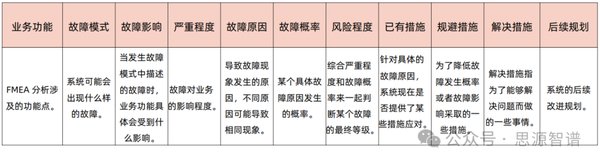
研究方法与发现
研究团队通过大量采样模型完成,并测量其中含有有害内容的比例,来计算各种提示使模型产生有害响应的概率。研究发现,高风险查询的数量与最高风险概率之间存在幂律分布。这意味着,尽管罕见,但某些特定类型的查询可能导致模型产生极高的风险响应。
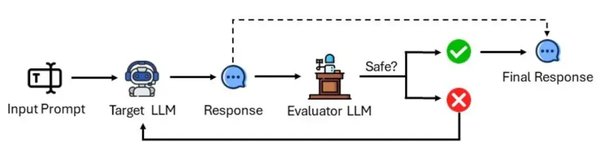
实际应用与意义
这项研究的结果表明,该方法在预测罕见风险方面比简单的基线方法更准确。对于LLM开发者来说,这意味着他们可以在部署模型之前,采取更加有针对性的措施来降低潜在风险。例如,开发者可以通过调整模型的训练数据或优化模型的提示处理机制,来减少模型产生有害响应的可能性。
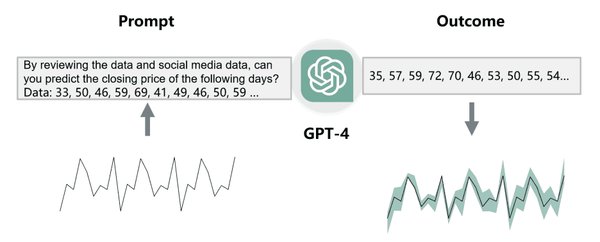
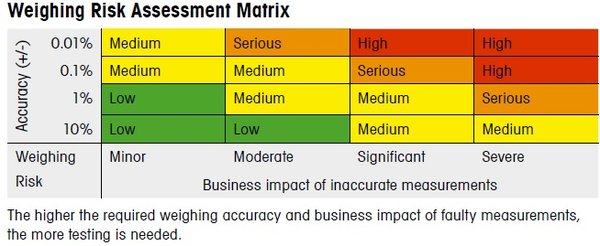
技术细节与挑战
在实际操作中,预测罕见行为风险并非易事。研究团队需要处理大量的数据,并设计复杂的算法来识别和量化这些风险。此外,模型的复杂性和多样性也增加了预测的难度。然而,通过不断优化算法和扩大数据样本,研究团队逐步提高了预测的准确性。
未来展望
随着LLM技术的不断发展,预测和控制模型行为风险将变得越来越重要。Anthropic的这项研究为未来的研究提供了新的方向,也为LLM的安全部署和应用奠定了坚实的基础。未来,我们期待看到更多类似的研究,以进一步推动人工智能技术的安全与可持续发展。
通过这项研究,我们不仅看到了Anthropic在Alignment Science领域的卓越贡献,也深刻认识到在LLM部署过程中,预测和控制风险的重要性。这不仅是对技术的挑战,更是对人类社会责任的体现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。