Hyper-YOLO:目标检测的技术革新
目标检测作为计算机视觉领域的核心技术之一,近年来取得了显著进展。YOLO(You Only Look Once)系列模型以其高效性和高精度成为业界的标杆,广泛应用于自动驾驶、安防监控、医疗影像等领域。然而,随着应用场景的复杂化,传统YOLO模型在处理跨层特征融合和复杂高阶特征关系时逐渐显现出局限性。为此,清华大学提出了一种全新的目标检测方法——Hyper-YOLO,首次将超图计算集成到目标检测网络中,为这一领域带来了突破性进展。

超图计算:捕捉高阶视觉关联
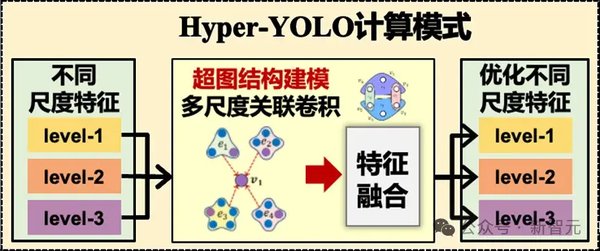
Hyper-YOLO的核心创新在于引入了超图计算(Hypergraph Computation)。与传统的图结构不同,超图能够捕捉更加复杂的高阶视觉关联,从而更有效地描述目标之间的多维度关系。这一机制通过以下方式提升了模型的性能:
-
跨层特征融合:传统YOLO模型在处理多尺度特征时,往往难以实现跨层信息的有效融合。而Hyper-YOLO通过超图计算,能够自然地整合不同层次的特征,提升模型对复杂场景的适应能力。
-
高阶特征关系建模:在复杂场景中,目标之间的关系往往涉及多个维度。超图计算通过捕捉这些高阶关联,使模型能够更准确地识别和定位目标。

性能提升:从理论到实践
Hyper-YOLO不仅在理论上具有创新性,在实际应用中也展现了显著的优势。与传统的YOLO模型相比,Hyper-YOLO在多个公开数据集上的检测精度均有明显提升,尤其是在复杂场景下的表现更为突出。例如,在自动驾驶场景中,Hyper-YOLO能够更准确地识别行人、车辆和交通标志,为安全驾驶提供了更可靠的保障。
此外,Hyper-YOLO的计算效率也得到了优化。通过引入动态分辨率机制,模型能够根据输入图像的分辨率自动调整计算资源,从而在保证精度的同时减少冗余计算。
未来展望:推动目标检测的边界
Hyper-YOLO的提出为目标检测领域开辟了新的研究方向。未来,随着超图计算技术的进一步发展,Hyper-YOLO有望在更多复杂场景中发挥其优势,例如医疗影像分析、工业检测等领域。同时,结合生成式AI和深度学习的最新进展,Hyper-YOLO还可能推动目标检测与其他AI技术的深度融合,为人工智能的广泛应用提供更强大的技术支持。
Hyper-YOLO不仅是目标检测领域的一次重要突破,更是超图计算与计算机视觉结合的成功范例。它的出现,为复杂场景下的目标检测提供了全新的解决方案,也为未来的技术发展指明了方向。




