
预训练模型的技术演进
预训练模型作为人工智能领域的核心技术之一,近年来经历了从单一任务到通用能力的跨越式发展。2022年,OpenAI推出的ChatGPT标志着大语言模型进入了一个全新的时代,而2024年的Sora模型则进一步推动了生成式AI从单模态向多模态的转变。这些突破的背后,离不开Transformer架构的持续创新与优化。
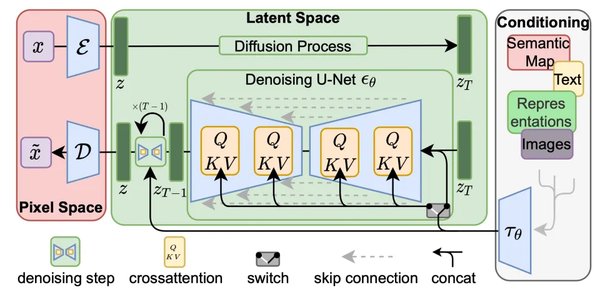
Transformer架构的变革
Transformer架构自2017年提出以来,已成为大模型的核心基础。其独特的自注意力机制和多层神经网络结构,使得模型能够高效处理长序列数据。2025年,图宾根马普所的研究团队提出了一种全新的递归深度架构,将递归思想融入Transformer,显著提升了模型的推理能力。这一创新不仅降低了模型的计算成本,还为小规模模型提供了新的能力提升路径。
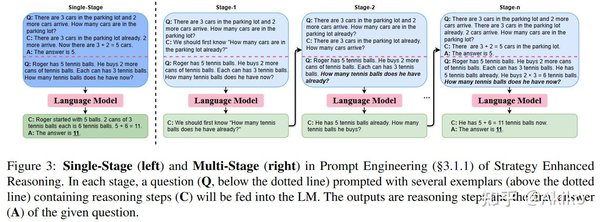
推理能力的突破
预训练模型的推理能力一直是研究的重点。OpenAI的GPT系列通过强化学习(RL)和思维链(CoT)技术,提升了模型的决策质量。而DeepSeek-R1则通过简单的奖励规则,鼓励模型自主形成长思考能力。这些技术突破表明,大模型正在从单纯的记忆与生成,向真正的推理与理解迈进。
多模态大模型的崛起
多模态大模型是预训练模型的另一重要方向。2024年,OpenAI的Sora模型展示了文生视频的强大能力,标志着生成式AI从单一模态向多模态的跨越。中国的文心一言、智谱清言等模型也在这一领域取得了显著进展,推动了多模态技术在医疗、教育等领域的应用。
应用场景的拓展
预训练模型的应用场景正从传统的自然语言处理扩展到更广泛的领域。例如,在电商平台中,大语言模型被用于自动生成视频标签,提升内容分析的效率。在医疗领域,多模态大模型结合图像与文本数据,辅助医生进行疾病诊断。这些应用不仅提高了工作效率,还为各行业带来了新的发展机遇。
未来展望
预训练模型的未来发展将更加注重推理能力的提升与计算效率的优化。递归深度架构、强化学习与多模态技术的结合,有望进一步推动大模型的能力边界。同时,开源模式的普及与商业化应用的深入,将为全球AI创新带来更多可能性。
预训练模型的技术突破与应用创新,正在重塑人工智能的版图。从Transformer架构的变革到多模态大模型的崛起,大模型在推理能力、计算效率和应用场景上的突破,展示了AI技术的无限潜力。未来,随着技术的持续进步,预训练模型将在更多领域发挥重要作用,推动人类社会迈向智能化的新阶段。








