
Claude 3.7 Sonnet的混合推理能力
Claude 3.7 Sonnet是Anthropic推出的新一代大型语言模型,也是市场上首款混合推理模型。它能够根据用户需求,在快速回应与深度思考之间灵活切换。在标准模式下,Claude 3.7 Sonnet延续了前代模型的强大指令理解与回应能力;而在延伸思考模式(Extended Thinking Mode)下,模型会在生成回应前进行自我反思,显著提升了数学、物理、编程设计等任务的准确度。这种设计理念源自Anthropic对“人类大脑”的模拟,正如人类既能快速反应,也能深入思考。

编程能力的显著提升
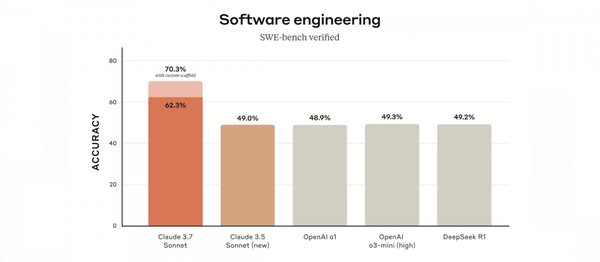
编程能力一直是Claude模型的强项,而Claude 3.7 Sonnet在这一领域更进一步。在SWE-bench Verified和TAU-bench基准测试中,Claude 3.7 Sonnet分别以62.3%和81.2%的准确度超越了Claude 3.5 Sonnet、OpenAI o1及DeepSeek R1。特别是在零售和航空场景中,其表现尤为突出。Anthropic官方表示,Claude 3.7 Sonnet能够从零到一生成复杂的网页与仪表板,并能应对大型项目,这使其成为开发者的理想选择。
Claude Code:开发者的高效助手
与Claude 3.7 Sonnet同步推出的还有Claude Code,这是一款针对开发者设计的命令行工具。Claude Code能够主动搜索与阅读代码、编辑文件、撰写与执行测试、提交GitHub变更,甚至与其他命令行工具整合。Anthropic内部测试显示,Claude Code可将原本手动45分钟的开发时间缩短至单次操作内完成,特别适用于测试驱动开发(TDD)、除错及大规模重构等情境。目前,Claude Code仍处于限制研究预览阶段,但未来将进一步提升其稳定性与应用范围。
混合推理模型的应用场景
Claude 3.7 Sonnet的混合推理能力使其在多种应用场景中表现出色:
-
日常应用与内容创作:标准模式适用于快速生成内容、编写代码等任务。
-
深度分析与复杂问题解决:延伸思考模式适合需要深入推理的场景,如数学问题求解、复杂编程任务等。
-
企业级应用:Claude 3.7 Sonnet能够处理现实世界中的软件工程任务,帮助企业提升效率。
未来展望与挑战
尽管Claude 3.7 Sonnet在编程与推理能力上取得了显著进步,但其仍需面对来自OpenAI、Google等竞争对手的挑战。例如,OpenAI的GPT-4.5在SWE-Lancer编程测试上表现优异,而Claude 3.7 Sonnet则需进一步提升其在该领域的表现。此外,Anthropic还需继续优化Claude Code的功能,以更好地满足开发者的需求。
Claude 3.7 Sonnet凭借其混合推理能力与强大的编程功能,为AI模型的发展树立了新标杆。无论是开发者还是企业用户,都能从中获得显著的价值。随着技术的不断进步,Claude 3.7 Sonnet有望在更多领域展现其潜力。





