
大模型基准测试的技术演进
近年来,大模型技术的快速发展对基准测试提出了更高要求。大模型基准测试不仅需要评估模型的准确性,还需综合考虑计算成本、部署难度、资源消耗和服务质量等多维度因素。中国科学院计算技术研究所北京泛在计算系统研究中心的研究方向之一正是大模型基准测试,这反映了学术界对这一领域的重视。
在技术层面,大模型基准测试涵盖功能测试、性能评估、准确性检验等多个方面。例如,功能测试确保模型按照预期设计执行任务,性能评估则关注模型的时间复杂度和空间复杂度。此外,准确性检验通过量化模型预测结果与实际情况的吻合程度,为模型优化提供数据支持。

算力基础设施的挑战与机遇
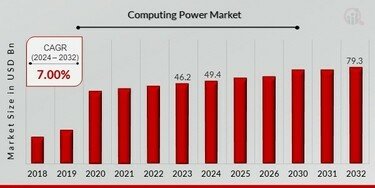
大模型的训练和推理对算力提出了极高要求。全国政协委员、中国科学院计算技术研究所研究员张云泉指出,当前国内算力市场存在供需失衡问题,高端算力紧缺,算力结构单一,这制约了大模型的迭代创新速度。他建议通过“超智融合”技术路线,建设大算力、全精度、高互联的高端智算中心,以应对这一挑战。
与此同时,开源大模型如DeepSeek的崛起为算力需求带来了新机遇。张云泉表示,随着DeepSeek等AI开源大模型的广泛应用,智算中心的算力需求显著增加,这为RISC-V等新兴架构提供了发展空间。RISC-V通过结合UMA(统一内存架构),能够减少计算和存储间的数据搬运开销,提升计算效率和整体性能。
大模型基准测试的应用场景
大模型基准测试在实际应用中面临诸多挑战。北京市计算中心有限公司专注于智能算法的开发与测试,通过多维度检测与评估,帮助客户优化算法表现,提升服务体验。其测试方法包括:
-
功能测试:验证模型在文本生成、机器翻译、图像识别等任务中的准确性。
-
性能评估:采用基准测试和负载测试,评估模型在不同负载下的稳定性。
-
准确性检验:通过准确率、精确率、召回率等指标量化模型预测结果。
-
稳定性与鲁棒性测试:确保模型在长时间运行或异常情况下的表现。
未来展望
随着大模型技术的不断演进,基准测试将成为确保其广泛应用的关键环节。张云泉建议,通过设立专项研发基金,打造开放共享的智算工具链和超智融合生态,推动大模型技术的产业化应用。此外,RISC-V等新兴架构的快速发展也为大模型提供了新的计算平台,未来有望在高性能计算领域实现突破。
大模型基准测试不仅是技术演进的必然需求,也是推动AI技术落地的重要保障。通过优化算力基础设施、完善测试方法,大模型技术将在更多领域发挥其潜力,为数字经济发展注入新动能。





