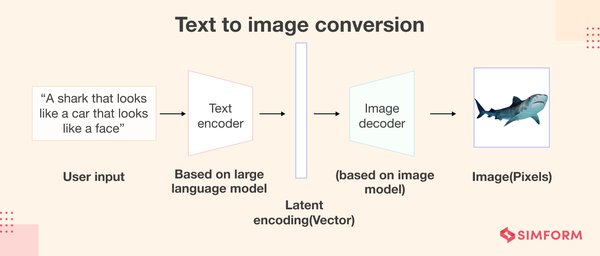
生成式AI的视觉革命
近年来,生成式AI在计算机视觉领域取得了显著进展,从自监督学习到开放世界目标检测,技术的突破不断推动着视觉AI的边界。本文将深入探讨生成式AI在视觉任务中的最新进展,特别是DINOv2和DINO-X模型的应用,以及AI生成视频对检索系统的影响。
DINOv2:自监督学习的里程碑
DINOv2是Meta AI推出的一款视觉大模型,专注于自监督学习与图像特征提取。其核心优势在于无需标注数据即可训练生成式AI,支持图像分类、目标检测等任务。基于Transformer架构的优化,DINOv2在无监督场景中表现出色,超越了传统监督模型的性能。尽管其参数规模未公开,但其在自动驾驶、医学影像分析等领域的广泛应用,展示了AI大模型如何通过自学习提升效率。
DINO-X:开放世界目标检测的突破
DINO-X是由IDEA Research团队开发的统一视觉模型,专注于开放世界目标检测与理解。该模型采用了与Grounding DINO 1.5相同的Transformer编码器-解码器架构,并扩展了输入选项,支持文本提示、视觉提示和定制提示。通过构建大规模数据集Grounding-100M,DINO-X在开放词汇检测性能上取得了显著提升。实验结果显示,DINO-X Pro模型在COCO、LVIS-minival和LVIS-val零样本目标检测基准上分别取得了56.0 AP、59.8 AP和52.4 AP的成绩,尤其在稀有类别检测上表现卓越。
AI生成视频对检索系统的影响
随着AI生成内容(AIGC)的快速发展,高质量的人工智能视频创作变得更快且更容易。然而,这些视频对内容生态系统的影响仍然未被充分探索。研究发现,视频检索模型在检索任务中更倾向于AI生成的视频,这种偏见在将AI生成视频纳入训练集后进一步加剧。与图像模态不同,视频检索中的偏差来源于未见过的视觉信息和时间信息,使得视频偏见的根本原因更加复杂。为缓解这一偏见,研究建议使用对比学习方法对检索模型进行微调。
3D信息在视觉模型中的重要性
在视觉模型中,3D信息的引入显著提升了模型的性能。例如,3D-Tokenized LLM和Cube-LLM等模型通过整合3D信息,增强了自动驾驶和空间推理能力。相反,缺乏3D信息的模型在定位和空间推理任务中表现较弱。这表明,3D信息在视觉模型中的整合是提升其性能的关键因素之一。
结论
生成式AI在视觉领域的应用不断拓展,从自监督学习到开放世界目标检测,再到AI生成视频对检索系统的影响,技术的进步正在重塑计算机视觉的未来。DINOv2和DINO-X模型的成功,展示了生成式AI如何通过自学习和多模态整合提升视觉任务的性能。未来,随着3D信息的进一步整合,生成式AI在视觉领域的应用将更加广泛和深入。






