引言
在深度学习领域,模型的高效部署是实现AI应用落地的关键步骤。Qualcomm AI Engine Direct作为高通推出的开发者工具,支持多种主流框架的模型转换,其中包括Onnx框架。本文将深入解析Qualcomm AI Engine Direct与Onnx框架的集成与应用,帮助开发者更好地理解其工作流程与优化策略。
Onnx框架与Qualcomm AI Engine Direct的集成
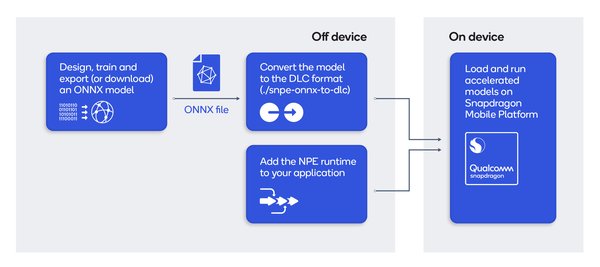
Onnx(Open Neural Network Exchange)是一种开放的神经网络交换格式,旨在实现不同深度学习框架之间的互操作性。Qualcomm AI Engine Direct通过提供转换器,支持将Onnx模型转换为可在骁龙平台上高效运行的格式。
转换器的工作流程
-
前端翻译:将Onnx模型转换为通用中间表示(IR)代码,确保模型结构的统一性。
-
通用IR代码:作为中间层,IR代码为后续的优化与转换提供基础。
-
量化器:通过量化技术,将浮点模型转换为低精度模型,从而提升运行效率并降低功耗。
-
Qnn转换器后端:将优化后的模型转换为骁龙平台支持的格式,确保模型在硬件上的高效执行。
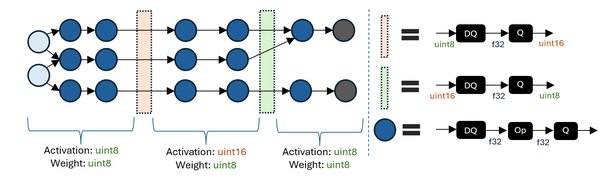
转换器的关键选项与参数
在模型转换过程中,开发者可以通过调整转换器的选项与参数,进一步优化模型的性能与精度。以下是一些关键选项:
-
量化模式:选择适合的量化策略(如动态量化或静态量化)以平衡精度与效率。
-
优化级别:设置不同的优化级别,以控制模型转换的复杂度与运行速度。
-
硬件适配:根据目标硬件的特性,调整模型参数以确保最佳性能。
开发者资源与支持
Qualcomm开发者专区为开发者提供了丰富的技术资源与支持,包括最新的资讯、工具链以及社区交流平台。通过加入开发者专区,开发者可以获取更多关于Onnx框架与Qualcomm AI Engine Direct的深度解析与实践案例,从而加速AI应用的开发与部署。
结语
Qualcomm AI Engine Direct与Onnx框架的集成为开发者提供了一条高效、灵活的模型部署路径。通过理解其工作流程与优化策略,开发者可以充分发挥骁龙平台的性能优势,实现AI应用的快速落地与高效运行。未来,随着技术的不断演进,这一集成方案将为更多创新应用提供强有力的支持。


