

Qualcomm AI Engine Direct简介
Qualcomm AI Engine Direct是一套强大的API,允许开发人员与Qualcomm SoC上的多种加速器进行交互,包括Kryo CPU、Adreno GPU和Hexagon处理器。通过这套API,AI计算可以被高效地委派给Hexagon处理器,从而显著提升模型推理性能。
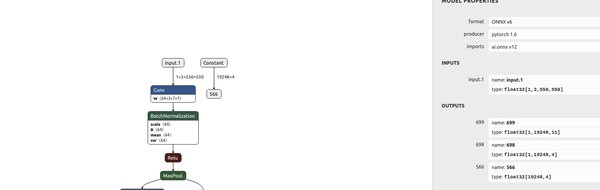
PyTorch模型转换流程
PyTorch模型的转换流程主要包括以下几个步骤:
-
前端翻译:将PyTorch模型转换为通用中间表示(IR)代码。
-
通用IR代码生成:生成适用于后续处理的中间代码。
-
量化器:对模型进行量化处理,以优化性能和资源利用率。
-
QNN转换器后端:将模型转换为Qualcomm神经网络(QNN)支持的格式。

转换器选项与参数详解
在模型转换过程中,转换器提供了丰富的选项和参数,以满足不同场景的需求。以下是一些关键配置:
-
输入类型与数据类型:通过
--input_type和--input_dtype选项,可以指定输入数据的类型和格式。 -
量化配置:使用
--quantization_overrides选项,可以覆盖默认的量化参数,从而优化模型精度。 -
输出路径:通过
--output_path选项,可以指定转换后模型的保存路径。 -
调试模式:启用
--debug选项,可以获取更详细的转换过程信息,便于排查问题。
转换器的高级功能
除了基本配置外,转换器还支持一些高级功能:
-
自定义IO配置:通过
--custom_io选项,可以指定自定义的输入输出配置,以适应特定硬件需求。 -
批量处理:使用
--batch选项,可以覆盖输入数据的批量维度,从而优化模型推理性能。 -
符号替换:通过
--define_symbol选项,可以替换输入维度中的符号变量,从而灵活调整模型输入。
实际应用与优化建议
在实际应用中,建议开发人员根据具体需求灵活配置转换器参数。例如,对于需要高精度的场景,可以启用--use_per_channel_quantization选项,以实现更精细的量化处理。此外,通过--algorithms选项,可以启用新的优化算法,如交叉层均衡化(CLE),以进一步提升模型性能。
通过深入理解Qualcomm AI Engine Direct的使用手册和PyTorch模型的转换流程,开发人员可以更高效地利用Qualcomm硬件加速器,实现AI模型的高性能推理。





