
引言
随着大语言模型(LLM)的广泛应用,Token限制成为了一个亟待解决的问题。OpenAI的GPT模型在处理长文本时,往往会因为Token数量的限制而无法生成完整的响应。为了解决这一问题,LangChain框架应运而生,它通过集成向量数据库和自注意力机制等技术,帮助用户绕过Token限制,生成任意长度的文本摘要。本文将深入探讨这些技术的原理及其在实际应用中的表现。
LangChain框架与Token限制
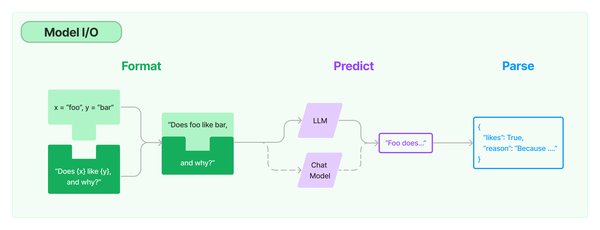
LangChain是一个强大的大语言模型接口框架,允许用户围绕大型语言模型快速构建应用程序和管道。其核心功能之一是能够直接与OpenAI的GPT模型集成,并通过以下方式解决Token限制问题:
-
向量数据库的引入:LangChain支持将文本转换为向量,并存储在向量数据库(如Chroma)中。通过这种方式,模型可以检索与问题最相关的文档片段,从而减少Token的使用量。
-
文档分割与检索:LangChain提供了文档加载器和文本分割器,能够将长文档分割为较小的块,并在需要时检索相关部分。这种方法不仅提高了处理效率,还避免了Token的浪费。
-
自注意力机制的应用:自注意力机制(Self-Attention)是Transformer模型的核心技术之一,它能够动态调整每个词的权重,从而捕捉长文本中的上下文关系。LangChain通过集成自注意力机制,进一步提升了模型对长文本的理解能力。

自注意力机制与长文本处理
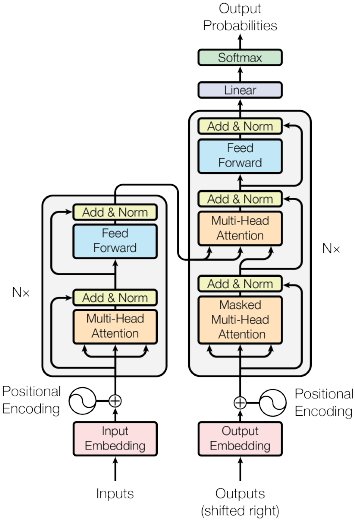
自注意力机制是自然语言处理中的关键技术,它通过以下步骤实现长文本的高效处理:
-
生成Q、K、V向量:为每个词生成查询(Query)、键(Key)和值(Value)向量,分别代表“我想关注什么”、“我有什么可被关注”以及“我实际携带的内容”。
-
计算注意力得分:通过点积运算计算每个词与其他词的相关性得分,得分越高表示相关性越强。
-
加权合并值向量:使用注意力得分对值向量进行加权求和,生成新的向量表示。这种方法能够有效捕捉长文本中的上下文关系,从而提升模型的预测准确性。
Gemini 1.5 Pro的突破
Gemini 1.5 Pro是Gemini家族的最新成员,它在长上下文理解方面取得了显著突破:
-
超长上下文处理能力:Gemini 1.5 Pro能够处理高达1000万Token的上下文,远超现有模型的20万Token限制。
-
多模态信息处理:该模型在文本、音频和视频等多模态信息的检索和理解任务中表现出色,实现了近乎完美的召回率。
-
计算效率提升:与Gemini 1.0 Pro相比,Gemini 1.5 Pro在性能提升的同时,显著降低了计算资源的消耗。
结论
LangChain框架通过集成向量数据库和自注意力机制等技术,有效解决了大模型的Token限制问题,为长文本处理提供了新的解决方案。与此同时,Gemini 1.5 Pro等先进模型在长上下文理解方面的突破,进一步拓展了大语言模型的应用边界。未来,随着这些技术的不断发展,大模型将在更多复杂场景中发挥重要作用。







