
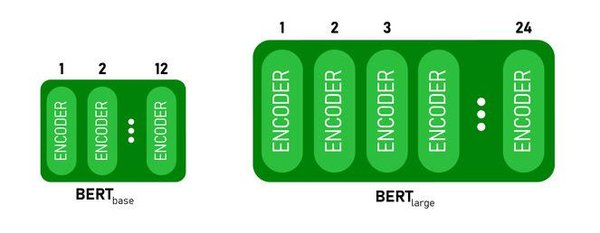
BERT模型的技术架构
BERT(Bidirectional Encoder Representations from Transformers)模型由Google在2018年提出,是一种基于Transformer架构的预训练语言模型。与传统的单向语言模型不同,BERT采用双向编码器,能够同时考虑上下文信息,从而在多项自然语言处理任务中取得了显著的成绩。
BERT的核心技术包括:
-
双向编码器:通过同时考虑前后文信息,提升语言理解能力。
-
预训练与微调:在大规模语料库上进行预训练,然后在特定任务上进行微调。
-
Transformer架构:利用自注意力机制,高效处理长距离依赖关系。
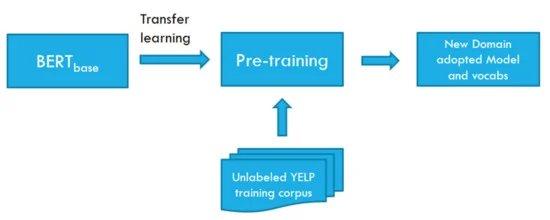
BERT模型的实际应用
BERT模型在多个领域展现了强大的应用潜力,包括但不限于:
-
搜索引擎优化:通过理解用户查询意图,提升搜索结果的准确性。
-
机器翻译:在多语言翻译任务中,BERT能够提供更流畅、准确的翻译结果。
-
情感分析:通过对文本的情感倾向进行判断,帮助企业进行市场分析和舆情监控。

安全与伦理问题
随着BERT等大模型的广泛应用,安全与伦理问题也日益凸显。主要问题包括:
-
数据隐私:大规模数据收集可能侵犯用户隐私。
-
模型偏见:训练数据中的偏见可能导致模型输出不公平或歧视性结果。
-
网络攻击:针对大模型的网络攻击,如DDoS攻击和钓鱼网站,可能对系统安全构成威胁。
中国在人工智能领域的战略布局
中国在人工智能领域的战略布局和成就备受瞩目。DeepSeek等国产大模型的崛起,打破了美国在人工智能行业的垄断格局,推动了中国AI技术的快速发展。中国政府通过政策扶持和资源投入,支持AI创新,特别是在“草根化”趋势下,激发了广大创业者的创新热情。
人工智能的未来展望
人工智能的未来充满机遇与挑战。随着技术的不断进步,AI将在更多领域发挥重要作用,如自动驾驶、医疗诊断和金融分析等。同时,确保AI技术的安全性和伦理性,将是未来发展的重要课题。
通过深入探讨BERT模型及其在人工智能领域的应用,我们不仅看到了技术的力量,也意识到了伴随而来的责任与挑战。未来,随着技术的不断演进,人工智能将继续塑造我们的世界,带来更多的可能性与希望。







