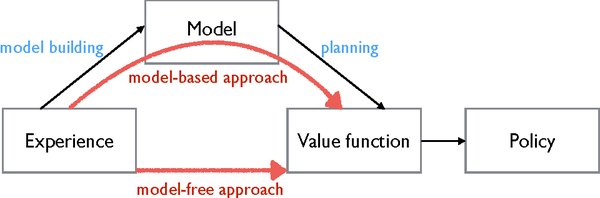
强化学习的革命性进展
近年来,DeepMind在强化学习(Reinforcement Learning, RL)领域取得了显著进展,特别是在基于模型的强化学习(Model-Based Reinforcement Learning, MBRL)方面。通过不断改进算法和技术,DeepMind的智能体在复杂环境中表现出了超越人类专家的能力。

Craftax-classic环境中的突破
DeepMind的最新研究聚焦于Craftax-classic环境,这是一个2D版的《我的世界》。该环境具有以下特点:
– 每次游戏环境随机生成,AI需要应对不同挑战。
– AI只能看到局部视野,增加了探索难度。
– 以成就层级设定奖励信号,要求深入且广泛的探索。
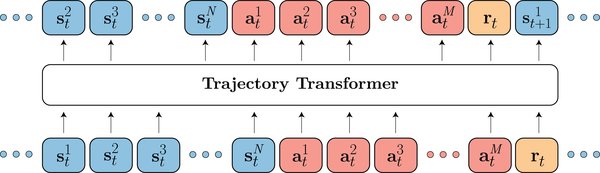
Transformer世界模型的应用
DeepMind的研究团队通过改进基于Transformer世界模型(Transformer World Model, TWM)的强化学习方法,取得了以下成果:
– 智能体在仅用100万步环境交互的情况下,获得了Craftax-classic 67.42%的奖励和27.91%的得分,显著超过了之前的最佳研究成果。
– 智能体的表现甚至超越了人类专家,展示了AI技术在复杂环境中的强大潜力。
核心技术与方法
研究团队在以下几个方面进行了改进:
1. Dyna方法:混合使用真实环境数据和TWM生成的虚拟数据来训练智能体,提高了训练效率。
2. 图像块最近邻标记器(NNT):将图像分解为不重叠的图像块,并使用NNT进行标记化,显著提高了智能体的奖励。
3. 块状教师强制(BTF):并行预测同一时间步的所有token,提高了训练速度和模型准确性。
实验结果与性能提升
通过逐步引入上述改进措施,智能体的性能得到了显著提升:
| 改进措施 | 奖励(%) | 得分(%) |
|---|---|---|
| 基线模型 | 46.91 | 15.60 |
| +Dyna方法 | 55.49 | 16.77 |
| +图像块分解 | 58.92 | 19.40 |
| +NNT | 64.96 | 23.91 |
| +BTF | 67.42 | 27.91 |
未来工作与展望
DeepMind团队计划将这些技术推广到其他更具挑战性的环境中,并探索使用优先经验回放来加速TWM的训练。此外,团队还考虑将大型预训练模型的能力与当前的标记器结合起来,以获得更稳定的代码本。
结论
DeepMind在强化学习领域的最新突破,不仅展示了AI技术在复杂环境中的强大潜力,也为未来的研究和应用提供了新的方向。通过不断改进算法和技术,DeepMind正在推动人工智能领域向更高的目标迈进。
通过本文,我们深入了解了DeepMind在强化学习领域的最新进展,特别是其在Craftax-classic环境中的突破性表现。这些成果不仅展示了AI技术的强大潜力,也为未来的研究和应用提供了新的方向。


.png)