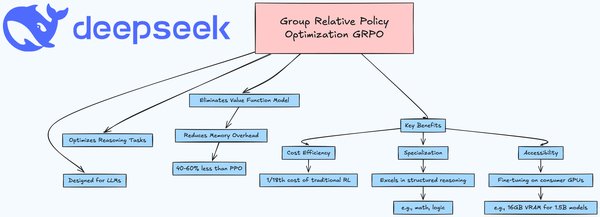
GRPO算法的革命性突破
Unsloth最近发布的GRPO算法在AI领域引起了广泛关注。这一算法通过内存效率线性算法和梯度检查点技术,将显存占用减少了90%,使得在仅5GB VRAM的情况下训练1.5B大模型成为可能。这一突破不仅显著提升了性能,还大大降低了硬件门槛,为更多研究者和开发者提供了便利。
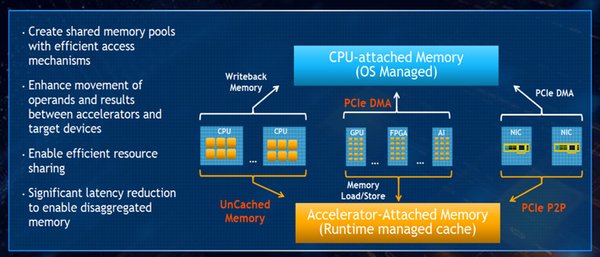
内存效率与资源共享
GRPO算法的另一大亮点是其与vLLM共享GPU/CUDA内存空间的能力。这种资源共享机制使得资源利用率提升了300%,进一步优化了计算资源的利用效率。对于需要处理大规模数据的AI项目来说,这种技术无疑是一大福音。
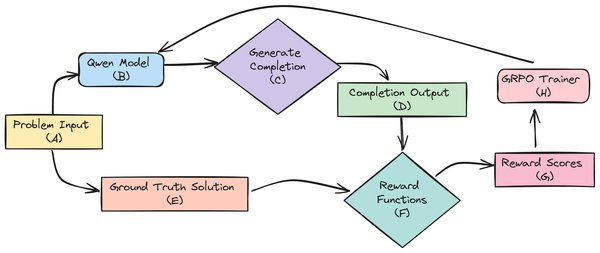

超长文本学习支持
传统序列长度限制一直是AI模型训练中的一大难题。GRPO算法通过独家FP8 KV缓存技术和动态4位量化技术,成功突破了这一限制,支持超长文本学习场景。这对于需要处理大量文本数据的应用,如自然语言处理和机器翻译,具有重要意义。
数学原理与开源生态
Unsloth不仅公开了GRPO算法的数学原理白皮书,还提供了完整的日志追踪系统,帮助研究者更好地理解和应用这一技术。此外,Unsloth还开源了完整代码库,全球开发者即日可下载并开始使用。这一举措极大地推动了AI技术的普及和发展。
生态扩展与未来展望
GRPO算法的生态扩展包括全球首个支持vLLM全量FP8缓存框架,以及新增Perplexity AI旗舰模型R1-1776的适配。这些扩展不仅丰富了GRPO算法的应用场景,还为其未来的发展奠定了坚实基础。可以预见,GRPO算法将在AI领域发挥越来越重要的作用。
通过以上分析,我们可以看到,GRPO算法不仅在技术上实现了重大突破,还在生态建设和开源共享方面做出了重要贡献。这一技术的广泛应用将为AI研究和应用带来深远影响。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。