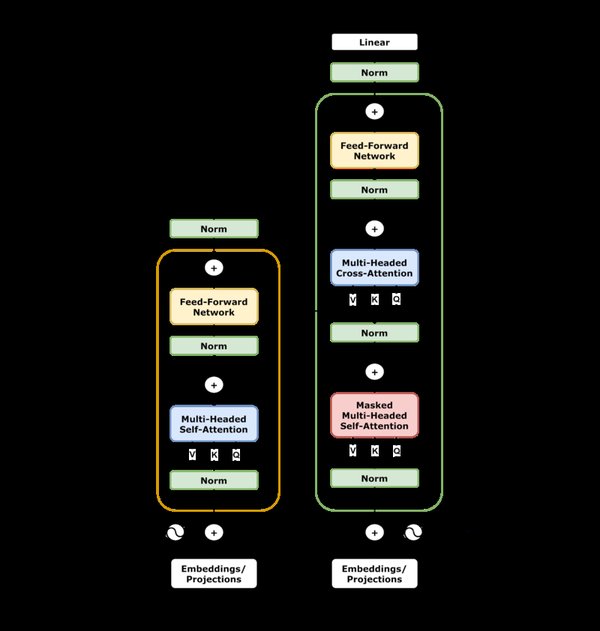
深度学习的起源与Transformer革命
深度学习的兴起可以追溯到2012年,当时加拿大多伦多大学的杰弗里·欣顿教授及其团队在图像识别领域取得了突破性进展。这一突破激发了AI领域的快速发展,尤其是在语音识别、图像识别和自然语言处理(NLP)等方向。然而,真正推动深度学习进入新纪元的是2017年Transformer架构的引入。
Transformer架构通过自注意力机制(Self-Attention)解决了传统循环神经网络(RNN)和长短期记忆网络(LSTM)在处理长程依赖性和顺序数据时的局限性。自注意力机制允许模型动态关注输入的不同部分,从而显著提升了上下文理解能力。这一创新为大规模语言模型(LLM)的发展奠定了基础。
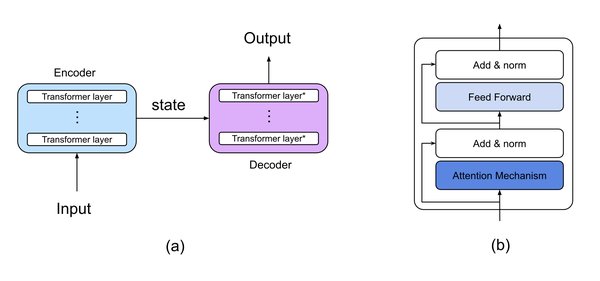
大语言模型的崛起
自Transformer架构问世以来,大语言模型(LLM)如GPT、BERT等迅速崛起。这些模型通过无监督学习从海量文本数据中提取语言模式,展现出强大的生成和理解能力。
-
GPT系列:OpenAI的GPT模型通过自回归训练实现了卓越的文本生成能力。GPT-3拥有1750亿参数,展示了少样本和零样本学习的潜力,能够在无需特定任务微调的情况下完成复杂任务。
-
BERT:谷歌推出的BERT模型采用双向训练方法,能够同时捕捉文本的前后文信息,在文本分类、问答等任务中表现出色。
这些模型的成功不仅推动了AI技术的发展,也为生成式AI(AIGC)的广泛应用铺平了道路。

多模态AI的兴起
随着技术的进步,AI从单一模态(如文本)向多模态(文本、图像、音频、视频)发展。2023年,OpenAI推出的GPT-4V和GPT-4o模型将语言能力与视觉、音频处理能力结合,开启了多模态AI的新时代。
-
GPT-4V:能够解释图像、生成标题,并在医疗和教育领域展现出巨大潜力。
-
GPT-4o:进一步整合音频和视频处理能力,支持实时交互和多媒体内容生成。
多模态AI的应用范围广泛,从医疗诊断到创意产业,正在深刻改变各行各业的工作方式。
推理模型的突破
2024年,AI开发的重点转向增强推理能力。OpenAI推出的o1模型通过思维链(Chain of Thought)技术,将复杂问题分解为更小的步骤,显著提升了模型在数学、科学和编程等领域的表现。
-
o1模型:在物理、化学和生物学等领域的测试中达到博士水平,展现了AI在复杂推理任务中的潜力。
-
DeepSeek-R1:中国深度求索公司推出的DeepSeek-R1模型通过强化学习技术,以低成本实现了高性能推理,推动了AI技术的普及化。
深度学习的挑战与未来
尽管深度学习取得了显著进展,但仍面临诸多挑战:
-
开发成本高:训练大规模模型需要巨大的计算资源和资金投入。
-
隐私与安全:AI生成内容的真实性和可信度引发担忧,如何确保数据隐私和模型安全成为重要议题。
-
偏见与伦理:模型可能继承训练数据中的偏见,如何在技术发展中兼顾伦理和公平性仍需探索。
展望未来,深度学习将继续推动AI技术的创新,特别是在AI智能体(AI Agent)和科研智能等领域。随着技术的不断进步,AI将在更多领域实现广泛应用,为人类社会带来深远影响。
正如中国新一代人工智能发展战略研究院执行院长龚克所言:“AI正在加速拓展人类的脑力劳动能力,推动生产力实现又一次质的飞跃。”在智能化的历史进程中,人类需要学会驾驭AI,确保其行驶在促进经济繁荣、环境保护和社会和谐的轨道上。





