引言
近年来,强化学习(Reinforcement Learning, RL)与推理时计算(Reasoning at Computation Time)的结合,成为人工智能领域的一大突破。这一方法不仅在编程竞赛中取得了显著进展,还为实现通用人工智能(AGI)指明了方向。本文将深入探讨这一技术的核心原理、应用案例及其未来展望。

强化学习与推理时计算的核心原理
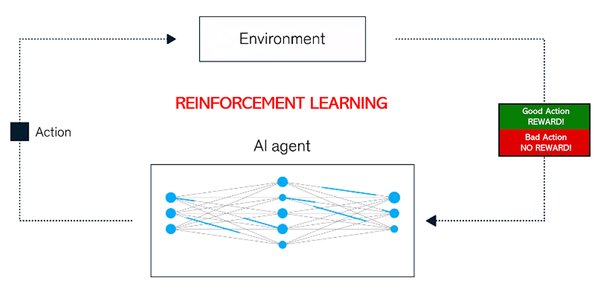
强化学习是一种通过试错学习优化策略的机器学习方法,而推理时计算则强调在模型推理过程中动态调整计算资源。两者的结合,使得AI模型能够在复杂任务中表现出更高的灵活性和智能性。
1. 强化学习的优势
-
试错学习:通过不断尝试和反馈,模型能够逐步优化其策略。
-
泛化能力:强化学习训练使模型能够在未见过的任务中表现出色。
2. 推理时计算的作用
-
动态调整:在推理过程中,模型可以根据任务需求动态分配计算资源。
-
效率提升:通过优化计算流程,模型能够在有限资源下实现更高的性能。
应用案例:DeepSeek-R1与AlphaGo
1. DeepSeek-R1模型
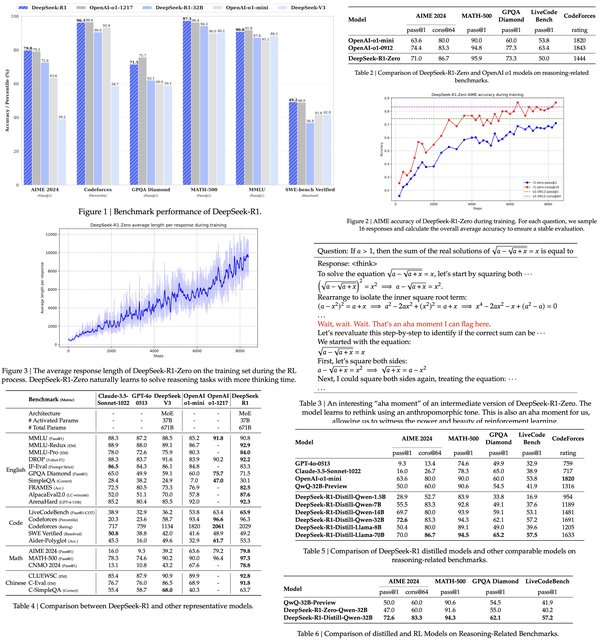
DeepSeek-R1模型通过基于规则的强化学习方法,展现了强大的推理能力。其训练成本较低,且具有可验证奖励的强化学习方法使其能够通过试错学习无限扩展智能。
-
技术贡献:
-
系统提示:强调模型在思考和回答过程中的细节。
-
严格的格式奖励函数:防止模型走捷径,确保其按照要求输出。
-
简单的训练方法:确保模型稳定收敛。
-
-
实验结果:经过仅5000个逻辑问题的训练,7B模型在AIME和AMC等数学竞赛中表现优异,准确率分别提高了125%和38%。
2. AlphaGo的成功经验
AlphaGo通过强化学习在围棋领域取得了突破性进展。其成功经验被应用于编程领域,并预测同样的技术将应用于所有STEM领域。
未来展望:AGI的实现与社会影响
1. AGI竞赛的开始
AGI竞赛已经开始,强化学习与推理时计算成为实现AGI的关键技术。通过不断优化模型推理能力和降低训练成本,AI模型将逐步逼近AGI的目标。
2. 潜在的社会影响
-
技术普惠:低成本AI模型的开发,将使更多企业和个人能够应用AI技术。
-
伦理挑战:随着AI智能的提升,如何确保其安全性和可控性成为重要议题。
结论
强化学习与推理时计算的结合,为AI模型的发展带来了新的突破。通过分析DeepSeek-R1模型和AlphaGo的成功经验,我们看到了这一技术在提升模型推理能力和降低训练成本方面的巨大潜力。未来,随着技术的不断进步,AI模型将在更多领域展现出其强大的智能性,为实现AGI奠定坚实基础。




.png)
