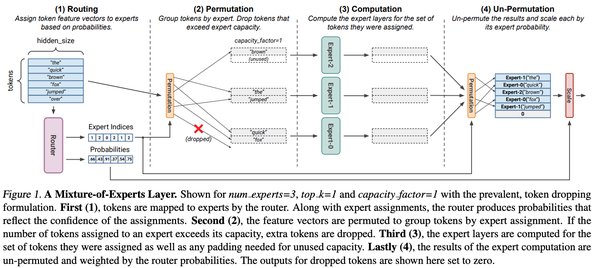
混合专家模型(MoE)的核心理念
混合专家模型(Mixture of Experts, MoE)是一种基于多专家协作的深度学习架构,旨在通过将复杂任务分解为多个子任务,并由不同专家模型分别处理,从而提高模型的整体性能。MoE的核心思想是将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配给一个或多个专家模型。这种“因材施教”的设计使得每个专家模型可以专注于处理特定领域的任务,从而提升模型的效率和精度。

MoE的架构与实现
MoE架构主要由两个核心组件组成:门控网络(GateNet)和专家模型(Experts)。
1. 门控网络:负责判定输入样本应由哪个专家模型处理。门控网络通过softmax函数输出权重,表示每个专家模型对处理输入数据的贡献。例如,如果模型有三个专家,门控网络可能输出权重为0.5、0.4和0.1,这意味着第一个专家对处理此数据的贡献为50%,第二个专家为40%,第三个专家为10%。
2. 专家模型:每个专家模型负责处理特定的输入子空间。在训练过程中,输入数据被门控网络分配到不同的专家模型中进行处理;在推理过程中,被选择的专家模型会针对输入数据产生相应的输出,最终通过加权组合形成预测结果。


MoE的稀疏性与效率
MoE的稀疏性是其显著优势之一。与传统Transformer模型不同,MoE模型仅对输入数据的特定部分执行计算,这种“条件计算”机制大幅降低了计算复杂度。例如,在Mixtral 8x7B MoE模型中,尽管总参数为56B,但由于只有FFN层被视为独立专家,且每个token仅使用两个专家,其推理速度类似于12B模型。
MoE在自然语言处理中的应用
MoE技术在自然语言处理领域取得了显著进展。例如,谷歌的GShard模型通过将Transformer架构中的前馈网络层替换为MoE层,成功将模型参数量扩展至6000亿。此外,Switch Transformer采用单专家策略,进一步降低了门控网络的计算负担和通信成本。
MoE的挑战与未来
尽管MoE在效率和性能上表现出色,但其对内存的高需求仍然是一个挑战。以Mixtral 8x7B为例,需要足够的VRAM来容纳47B参数的稠密模型。未来,随着应用场景的复杂化和细分化,MoE有望在多模态大模型领域发挥更大的作用,成为大模型研究的新方向之一。
结语
混合专家模型(MoE)通过多专家协作和稀疏性设计,为大模型时代提供了高效的解决方案。随着技术的不断演进,MoE将在自然语言处理、计算机视觉和多模态领域继续引领创新,推动深度学习技术的发展。






