

TPU的起源与发展
TPU(Tensor Processing Unit)是由Google于2016年推出的专用处理器,旨在加速神经网络等机器学习算法的计算任务。与传统的CPU和GPU相比,TPU在矩阵运算和深度学习任务中表现出更高的效率和性能。Google的TPU最初用于其数据中心,优化了搜索、翻译和图像识别等AI应用的计算效率。
TPU的核心优势在于其针对张量运算的硬件优化,能够高效处理大规模的矩阵乘法、卷积运算等深度学习任务。Google的TPU经历了多代演进,从最初的TPU v1到最新的TPU v4,每一代都在计算能力、能效和扩展性上实现了显著提升。
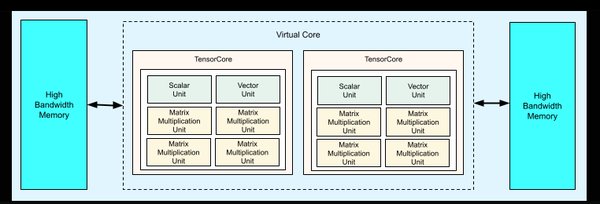
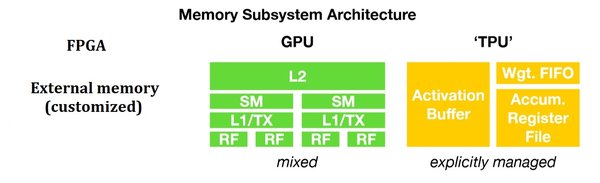
TPU的技术架构与优势
TPU的技术架构围绕张量运算设计,主要特点包括:
1. 专用硬件加速:TPU专为神经网络计算优化,支持高效的矩阵乘法和卷积运算。
2. 高吞吐量:TPU通过大规模并行计算,显著提升了AI任务的吞吐量。
3. 低功耗设计:相比GPU,TPU在相同计算任务下功耗更低,更适合大规模部署。
4. 可扩展性:Google通过TPU Pod技术,将多个TPU连接成集群,支持更大规模的AI模型训练。

TPU的市场应用与挑战
TPU广泛应用于深度学习、自然语言处理、计算机视觉等领域。Google的TPU不仅用于其内部AI服务,还通过Google Cloud向外部企业提供计算资源。然而,TPU的普及也面临一些挑战:
1. 生态依赖:TPU的软件生态主要依赖Google的TensorFlow框架,对其他框架的支持有限。
2. 成本与可及性:TPU的硬件成本较高,且主要面向大型企业和云服务商,中小企业难以负担。
3. 市场竞争:随着英伟达、AMD等厂商推出高性能AI芯片,TPU的市场份额面临激烈竞争。
国产TPU的崛起:中昊芯英的突破
在全球AI芯片竞争的背景下,中国企业在TPU领域也取得了重要进展。科德教育参股的中昊芯英是国内掌握TPU架构训推一体AI芯片核心技术的公司。中昊芯英的TPU芯片不仅在性能上与国际领先水平接轨,还在训推一体化设计上实现了创新,能够同时支持模型训练和推理任务,显著降低了AI应用的门槛。
中昊芯英的技术突破主要体现在以下几个方面:
1. 训推一体设计:通过硬件架构优化,实现了训练与推理任务的高效切换,提升了芯片的通用性。
2. 自主知识产权:中昊芯英掌握了TPU架构的核心技术,打破了国外厂商的技术垄断。
3. 应用场景拓展:中昊芯英的TPU芯片已广泛应用于教育、医疗、智能制造等领域,推动了AI技术的国产化进程。
TPU的未来展望
随着AI技术的快速发展,TPU作为专用AI芯片的重要性日益凸显。未来,TPU的发展方向可能包括:
1. 多框架支持:扩展对PyTorch、MXNet等主流深度学习框架的支持,降低生态依赖。
2. 边缘计算优化:开发适用于边缘设备的低功耗TPU,推动AI在物联网、自动驾驶等领域的应用。
3. 国产化加速:中昊芯英等中国企业将继续推动TPU技术的自主创新,提升中国在全球AI芯片市场的竞争力。
结语
TPU作为AI芯片领域的核心技术,正在推动人工智能的快速发展。从Google的TPU到中昊芯英的国产化突破,TPU的技术演进和市场应用展示了AI芯片的广阔前景。未来,随着技术的不断创新和国产化的深入推进,TPU将在全球AI生态中发挥更加重要的作用。








