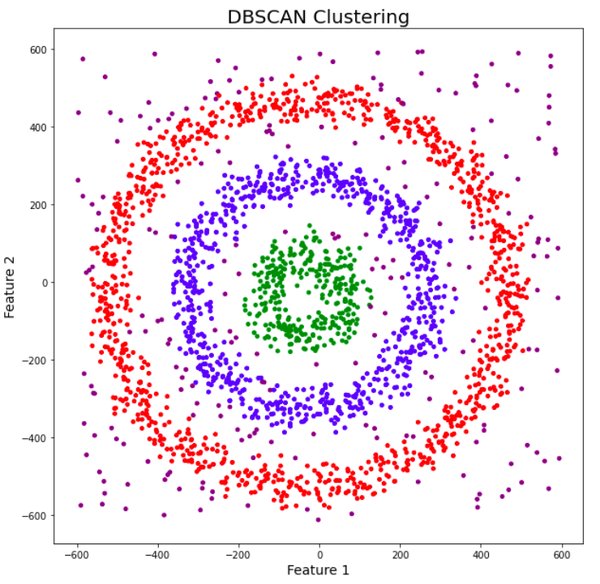
DBSCAN算法简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,广泛应用于数据挖掘和机器学习领域。与传统的K-means算法不同,DBSCAN能够识别任意形状的簇,并且能够有效处理噪声数据。然而,在高维数据中,DBSCAN面临“维度灾难”的挑战,导致聚类效果不佳。

高维数据中的挑战
在高维数据中,数据分布通常较为稀疏,使得DBSCAN难以识别有意义的簇。这种现象被称为“维度灾难”。为了克服这一挑战,研究者们提出了多种优化策略。
参数调优
DBSCAN的性能高度依赖于两个关键参数:邻域半径(epsilon)和最小点数(minPts)。在高维数据中,选择合适的参数尤为重要。以下是一些常用的参数调优方法:
– 网格搜索:在参数空间中进行系统搜索,找到最优的参数组合。
– 轮廓系数:通过轮廓系数评估不同参数设置下的聚类质量,选择最优参数。
降维技术
在高维数据中,降维技术可以显著提升DBSCAN的聚类效果。常用的降维方法包括:
– 主成分分析(PCA):将高维数据投影到低维空间,保留主要特征。
– t-SNE:通过非线性映射将高维数据降维,保留数据间的局部结构。
高级聚类方法
近年来,研究者们提出了多种高级聚类方法,以提升DBSCAN在高维数据中的性能。例如:
– 块对角引导DBSCAN:通过构建相似性图并进行图排列,简化簇的识别过程。这种方法在多个基准数据集上表现出色,展示了其在复杂数据环境中的潜力。
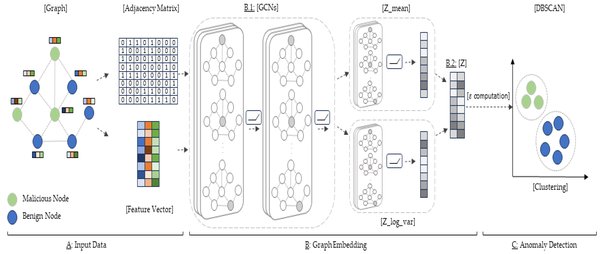
DBSCAN在网络信息安全中的应用
DBSCAN在机器学习网络信息安全领域也有广泛应用。例如,在监测网络欺诈和黑客攻击中,DBSCAN可以用于异常检测,识别出不符合正常行为模式的数据点。通过结合其他机器学习技术,如分类模型和序列预测,DBSCAN能够有效提升网络安全的监测能力。
结论
通过参数调优、降维技术和高级聚类方法,DBSCAN在高维数据中的性能得到了显著提升。这些优化策略不仅提高了聚类的准确性,还扩展了DBSCAN在复杂数据环境中的应用范围。未来,随着机器学习技术的不断发展,DBSCAN在网络信息安全等领域的应用前景将更加广阔。
| 优化策略 | 描述 | 应用场景 |
|---|---|---|
| 参数调优 | 通过网格搜索和轮廓系数选择最优参数 | 高维数据聚类 |
| 降维技术 | 使用PCA和t-SNE降低数据维度 | 复杂数据结构 |
| 高级聚类方法 | 块对角引导DBSCAN提升聚类效果 | 基准数据集 |
通过上述方法,DBSCAN在高维数据中的表现得到了显著改善,为数据挖掘和机器学习领域提供了强大的工具。





