Transformer 架构的起源与突破
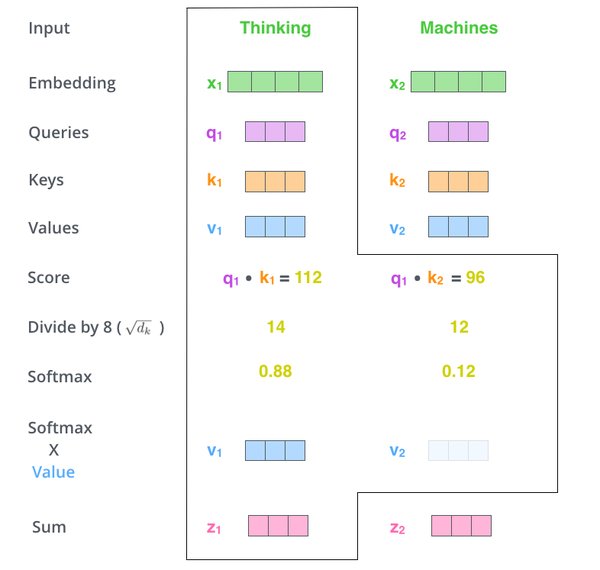
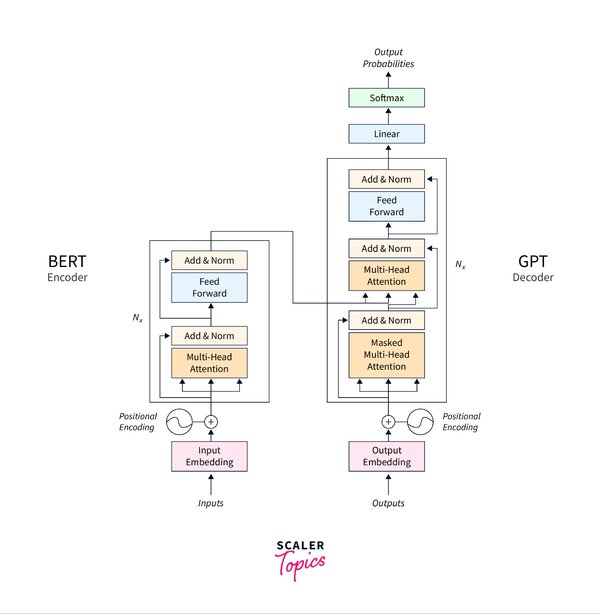
2017 年,谷歌团队提出了 Transformer 架构,这一技术彻底改变了自然语言处理领域。雅各布・乌斯克尔特作为核心成员之一,在 TED AI 大会上回顾了这一技术的诞生历程。Transformer 的核心在于其自注意力机制(Self-Attention),它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),实现了并行化处理,大幅提升了模型效率。
尽管团队对 Transformer 的潜力充满信心,但他们并未完全预见到它在生成式人工智能中的广泛应用。如今,Transformer 已成为 ChatGPT、Sora 等模型的基础架构,推动了生成式 AI 的快速发展。
Transformer 在 Sora 中的应用
Sora 作为一种先进的生成式模型,依赖于 Transformer 架构处理复杂的序列数据。例如,在视频超分辨率(VSR)任务中,Sora 利用 Transformer 块生成和优化高分辨率视频的潜在表示。这种基于 Transformer 的设计不仅提升了视频质量,还显著提高了处理效率。
然而,Transformer 在处理长序列数据时仍面临计算效率的挑战。标准注意力机制的二次复杂度限制了模型的上下文窗口,难以处理长文档或高分辨率输入。尽管已有稀疏注意力等优化技术,但仍需进一步创新以平衡计算效率与模型性能。
生成式 AI 的挑战与未来方向
生成式 AI 模型的训练数据中可能存在偏见,例如某些文化或性别相关的词汇被错误关联。这种偏见可能影响模型的输出结果,尤其是在扩散模型等基于提示词生成的任务中。因此,如何在训练过程中消除偏见,成为生成式 AI 研究的重要课题。
未来,Transformer 架构有望在更多领域发挥潜力。乌斯克尔特创办的 Inceptive 公司正致力于将深度学习技术引入生物化学领域,开发“生物软件”以设计更高效的药物。这种跨界应用展示了 Transformer 技术的广泛适用性。
结语
Transformer 架构的提出是人工智能领域的一次革命性突破,它不仅推动了生成式 AI 的发展,还为生物化学等跨学科研究提供了新的工具。随着技术的不断演进,Transformer 将在更多领域展现其独特价值,为人类带来更多创新与突破。







