Transformer架构的起源与影响
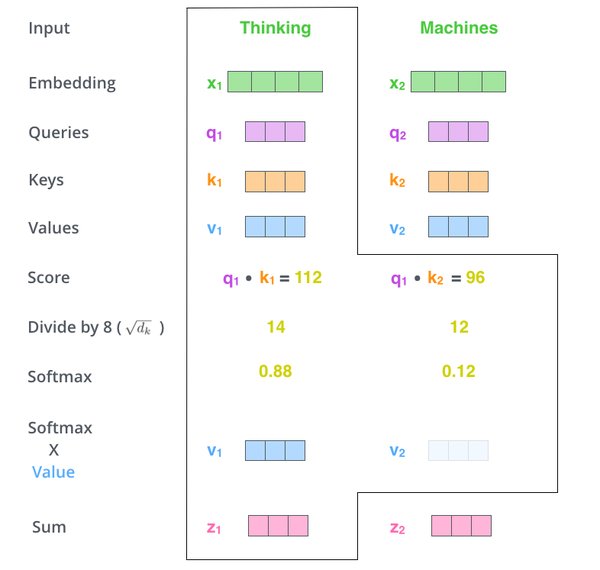
2017年,Google研究员Ashish Vaswani等人提出了Transformer架构,这一突破性技术彻底改变了自然语言处理(NLP)领域。Transformer的核心在于其自注意力机制(Self-Attention),它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),使得模型能够更高效地处理长序列数据。这一架构不仅在语言理解任务中表现出色,还为后续的生成式AI模型如ChatGPT和Sora奠定了技术基础。
计算效率:Transformer面临的挑战
尽管Transformer架构在性能上取得了显著突破,但其计算效率问题仍然是一个亟待解决的难题。标准的注意力机制在处理长序列时,计算复杂度呈二次方增长,这限制了模型在处理长文档或高分辨率输入时的能力。例如,许多模型的上下文窗口通常只能容纳几千个token,这阻碍了其对长文本或视频内容的完整理解与生成。
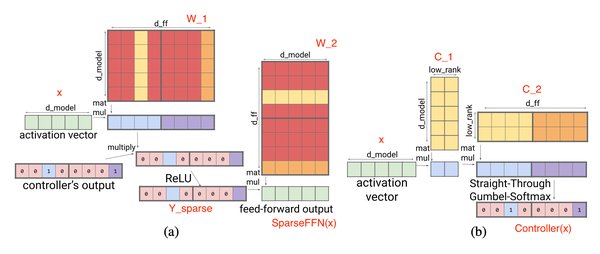
为解决这一问题,研究者们提出了多种优化方案,包括稀疏注意力机制和线性注意力变体。此外,结合其他机制的混合架构、保留重要长程连接的结构化稀疏模式,以及针对硬件加速器设计的算法,都是未来研究的重点方向。

Sora模型与视频生成中的Transformer应用
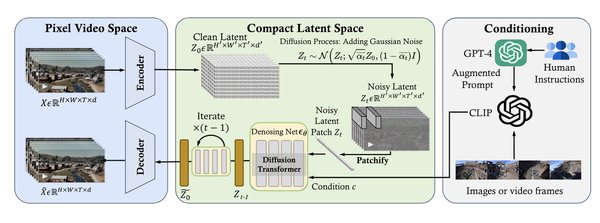
Sora模型作为生成式AI的代表,充分利用了Transformer架构的优势,尤其是在视频生成领域。研究表明,Sora模型通过引入多token集和元因果token,实现了高效的并行解码。然而,在视频生成过程中,由于相邻帧的指示特征相似,模型难以准确捕捉连续且细微的运动变化,这可能导致图像结构崩溃和视频流畅性下降。
此外,Sora模型还结合了视频扩散模型(VDM)技术,通过潜在空间中的3D高分辨率视频生成与优化,显著提升了视频超分辨率(VSR)任务的性能。这一方法不仅增强了视频的细节表现力,还通过迭代优化减少了与低分辨率观察值之间的差异。
AI训练数据中的偏见问题
在AI模型的训练过程中,数据偏见是一个不容忽视的问题。例如,2017年的一项研究发现,AI模型倾向于将欧洲名字与“愉悦”关联,而将非洲裔美国人名字与负面情绪联系起来。此外,“女性”和“女孩”等词汇更常与艺术领域相关,而“男性”则更多地与科学和数学领域挂钩。这种偏见在生成式AI模型中尤为突出,尤其是在基于用户输入的提示词生成内容时,可能导致偏见的进一步放大。
未来展望
Transformer架构的革新为AI技术的发展开辟了新的道路,而Sora模型则展示了其在视频生成领域的巨大潜力。然而,计算效率和数据偏见问题仍然是未来研究的关键挑战。通过不断优化算法设计和加强数据治理,AI模型将能够更好地服务于人类社会的多样化需求。
主要技术优化方向
| 优化方向 | 具体方法 |
|---|---|
| 稀疏注意力机制 | 减少计算复杂度,保留重要连接 |
| 线性注意力变体 | 提高长序列处理效率 |
| 混合架构 | 结合其他机制,提升模型性能 |
| 硬件加速器设计 | 针对GPU等硬件优化算法 |
| 数据偏见治理 | 加强数据筛选与标注,减少模型偏见 |
通过以上技术的不断突破,Transformer架构及其衍生模型如Sora将在未来AI领域继续发挥重要作用。






