DeepSeek V2:技术创新的里程碑
DeepSeek V2的发布标志着中国在大模型技术领域的一次重大突破。作为DeepSeek公司继DeepSeek LLM之后的第二代模型,V2不仅在性能上实现了显著提升,更通过技术创新大幅降低了训练和推理成本,成为行业内的标杆。
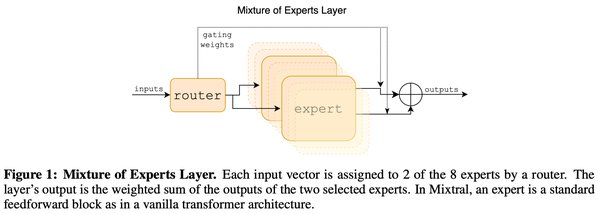
混合专家模型(MoE)的革新
DeepSeek V2采用了混合专家模型(Mixture of Experts, MoE)架构,全参数量达到236B,但激活参数仅为21B。这种设计使得模型在推理时仅需激活部分专家,从而大幅降低了计算成本。与传统的稠密模型相比,MoE架构通过稀疏计算实现了高效的推理,尤其是在处理大规模数据时表现尤为突出。
MoE的核心优势:
– 专家细分:V2采用了160个专家,远高于传统MoE模型的8或16个专家。这种细粒度设计使得每个专家能够更专注于特定领域,提升了模型的整体性能。
– 共享专家机制:除了专有专家,V2还引入了共享专家,用于处理通用任务。这种设计既保证了模型的灵活性,又提高了资源利用率。
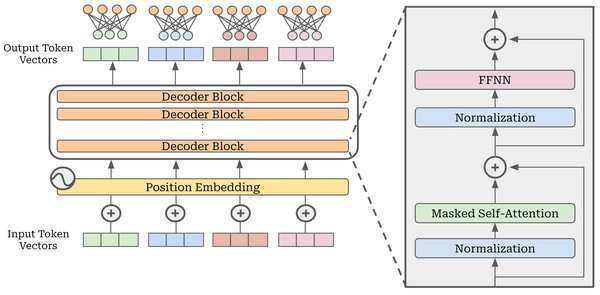
多头潜在注意力(MLA)的突破
DeepSeek V2的另一大创新是多头潜在注意力(Multi-Head Latent Attention, MLA)。MLA通过将Key-Value缓存压缩为潜在向量,显著减少了推理时的存储需求,同时提升了生成速度。
MLA的技术亮点:
– 低维压缩:MLA将高维的Key-Value向量压缩为低维潜在向量,减少了93%的KV缓存,极大降低了部署成本。
– 高效推理:通过低维压缩,V2的生成吞吐量比DeepSeek 67B模型提升了5.76倍,推理速度显著提高。
低成本训练与行业影响
DeepSeek V2不仅在技术上实现了创新,还在成本控制上取得了显著成果。相比DeepSeek 67B模型,V2的训练成本降低了42.5%,推理成本更是大幅下降。这种低成本高效率的设计,直接引发了行业内的大模型价格战。
成本控制的关键:
– FP8低精度训练:V2在训练中采用了FP8低精度浮点运算,进一步降低了计算成本。
– 工程优化:通过精细的工程优化,V2在硬件利用率和通信效率上达到了极致,确保了训练的高效性。
行业影响与未来展望
DeepSeek V2的发布不仅展示了中国在大模型技术上的创新能力,也为全球AI行业提供了新的思路。其低成本高效率的设计,使得更多企业和研究机构能够参与到大模型的开发与应用中,推动了AI技术的普及与发展。
V2的行业影响:
– 价格战的开端:V2的低成本设计直接引发了行业内的大模型价格战,推动了技术的商业化进程。
– 技术创新的示范:V2的成功证明了通过技术创新,可以在不牺牲性能的前提下大幅降低成本,为其他企业提供了宝贵的经验。
结语
DeepSeek V2作为中国大模型技术创新的典范,通过混合专家模型和多头潜在注意力技术,不仅实现了性能的飞跃,还大幅降低了训练和推理成本。其成功不仅展示了中国在AI领域的潜力,也为全球AI行业提供了新的发展方向。未来,随着DeepSeek技术的不断迭代,我们有理由相信,中国将在全球AI舞台上扮演更加重要的角色。







