引言
随着人工智能技术的快速发展,Transformer架构及其衍生的BERT模型已成为自然语言处理(NLP)领域的核心技术。本文将从基础知识出发,深入探讨Transformer和BERT的核心原理、应用场景以及学习资源,帮助读者从理论到实践全面掌握这些技术。
Transformer架构的核心原理
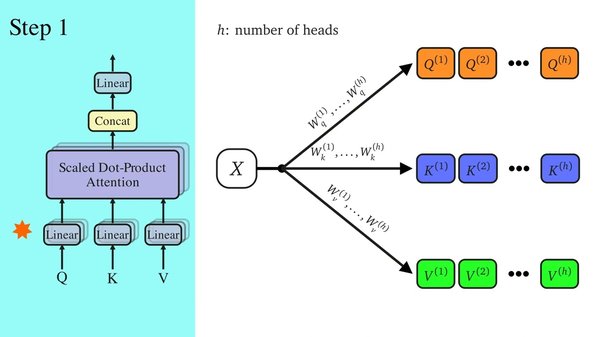
Transformer架构是BERT模型的基础,其核心在于自注意力机制(Self-Attention)和多头注意力机制(Multi-Head Attention)。这些机制使得模型能够捕捉输入序列中的长距离依赖关系,从而在NLP任务中表现出色。
自注意力机制
自注意力机制允许模型在处理每个输入时,同时关注序列中的其他部分。这种机制通过计算输入序列中每个位置之间的相关性得分,来决定每个位置对输出的贡献。
多头注意力机制
多头注意力机制通过并行计算多个自注意力头,进一步增强了模型的表达能力。每个注意力头可以捕捉不同子空间中的信息,从而提升模型的整体性能。
BERT模型的应用与优化
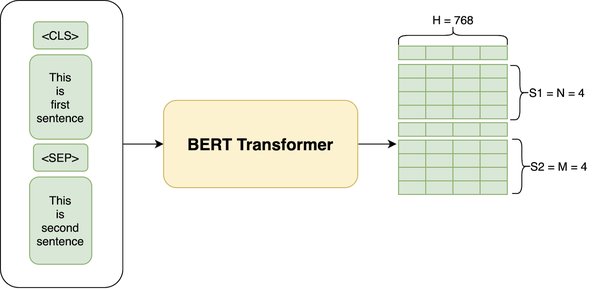
BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer架构的预训练模型,通过双向编码器实现了对上下文信息的全面捕捉。
预训练与微调
BERT的预训练过程包括在大规模文本数据上进行掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务。预训练完成后,BERT可以通过微调适应各种下游任务,如文本分类、问答系统和命名实体识别。
模型优化技术
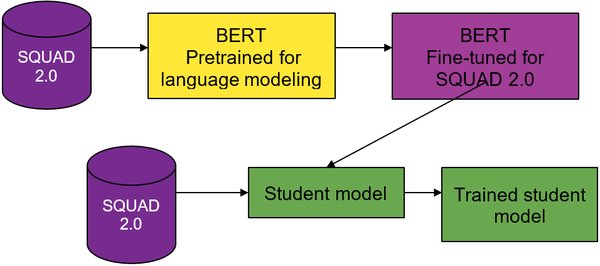
为了提升BERT的效率和性能,研究者们提出了多种优化技术,包括知识蒸馏、剪枝和量化。这些技术能够在保持模型性能的同时,显著减少模型的计算和存储开销。
实践项目与学习资源
理论学习固然重要,但实践是掌握大模型技术的关键。以下是一些适合入门的实践项目和学习资源:
实践项目
- 文本分类:使用BERT或GPT模型对IMDB电影评论数据集进行分类。
- 机器翻译:使用Transformer模型实现英汉翻译,基于WMT英汉平行语料库。
- 问答系统:基于BERT或GPT构建一个简单的问答系统,使用SQuAD问答数据集。
- 图像生成:使用GAN或扩散模型生成图像,基于CIFAR-10、MNIST数据集。
学习资源
- 在线课程:推荐Andrew Ng的《深度学习专项课程》。
- 书籍:《动手学深度学习》(李沐)和《自然语言处理入门》(Jacob Eisenstein)。
- 论文与博客:关注arXiv上的最新论文和Medium上的技术博客。
职业发展建议
在大模型领域,构建个人品牌和持续学习是职业发展的关键。通过参与开源项目、分享学习心得和关注行业动态,读者可以不断提升自己的技术能力和职业竞争力。
结论
Transformer架构和BERT模型在NLP领域展现了强大的能力,通过系统学习、实践项目和参与开源社区,读者可以逐步掌握这些技术,并在职业发展中取得成功。希望本文能为你的学习之路提供帮助,祝你在大模型领域大展宏图!
“`markdown
| 项目名称 | 数据集 | 模型 |
|---|---|---|
| 文本分类 | IMDB电影评论数据集 | BERT/GPT |
| 机器翻译 | WMT英汉平行语料库 | Transformer |
| 问答系统 | SQuAD问答数据集 | BERT/GPT |
| 图像生成 | CIFAR-10、MNIST | GAN/扩散模型 |
“`



