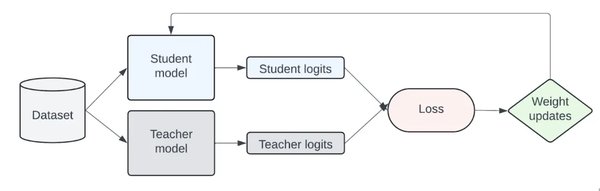
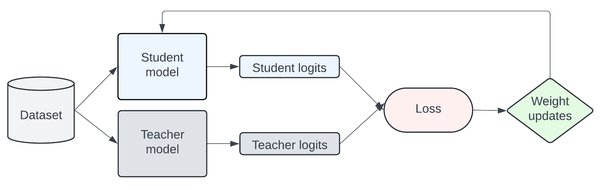
模型蒸馏算法的基本原理
模型蒸馏(Distillation)是一种将复杂模型(教师模型)的知识转移到更小、更高效模型(学生模型)的技术。这一概念由Hinton等人在2015年提出,其核心思想类似于教师教导学生。通过蒸馏,学生模型不仅能学习到教师模型的输出结果,还能掌握其内部的知识表示,从而实现高效的知识迁移。
模型蒸馏的应用场景
-
模型压缩:将大型模型的知识转移到小型模型中,降低计算资源需求。
-
知识迁移:在跨领域任务中,利用已有模型的知识加速新模型的训练。
-
轻量化部署:在资源受限的设备(如移动端)上部署高效模型。
-
多模态学习:将视觉、文本等多模态知识整合到单一模型中。

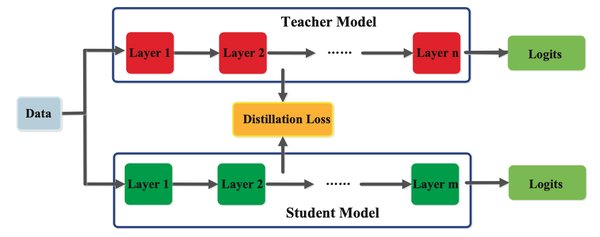
模型蒸馏的实现方法
模型蒸馏的具体实现通常包括以下步骤:
-
训练一个复杂的教师模型,使其在目标任务上表现优异。
-
使用教师模型的输出(如softmax概率)作为学生模型的训练目标。
-
通过优化学生模型的损失函数,使其逐步逼近教师模型的表现。
开源工具与资源
近年来,许多开源工具库为模型蒸馏提供了便捷的实现方式。例如,XTuner是一个高效、灵活、全能的轻量化大模型微调工具库,支持多种微调算法,如QLoRA、LoRA和全量参数微调。这些工具大大降低了开发者实践模型蒸馏的门槛,推动了该技术的广泛应用。
未来展望
随着深度学习技术的不断发展,模型蒸馏算法在高效训练和轻量化部署领域的重要性日益凸显。未来,结合多模态学习、自监督学习等前沿技术,模型蒸馏有望在更多场景中发挥其独特优势,为AI模型的开发和应用带来更多可能性。
通过理解并实践模型蒸馏算法,开发者可以更高效地训练和部署AI模型,为实际应用提供强有力的技术支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...







AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。