
隐私保护联合学习技术的背景与意义
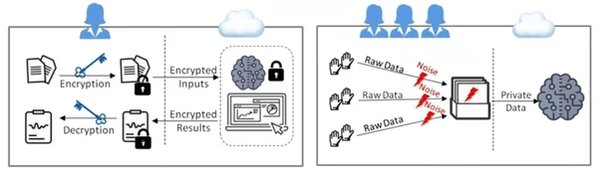
随着金融科技的快速发展,数据安全与隐私保护成为行业关注的焦点。传统的欺诈检测方法依赖于集中式数据处理,容易引发数据泄露风险。隐私保护联合学习技术(Federated Learning with Privacy Preservation)应运而生,它能够在保护数据隐私的同时,实现多方数据的协同学习与模型优化。
神户大学与多家银行及研究机构合作,利用这一技术进行了欺诈性汇款检测的示范实验,为金融行业的数据安全与欺诈防范提供了新的解决方案。

实验设计与技术实现
本次实验分为两个主要部分:受害交易检测和欺诈账户检测。通过联合学习模式,各参与方在不共享原始数据的情况下,共同训练模型,显著提高了检测精度。以下是实验的主要技术特点:
- 数据隐私保护:采用差分隐私和加密技术,确保数据在传输和计算过程中的安全性。
- 模型优化:通过联合学习,各方共享模型更新而非原始数据,避免数据泄露风险。
- 混合学习模式:在欺诈账户检测中,结合了传统机器学习与深度学习技术,检出率达到80%以上。

实验结果与应用价值
实验结果显示,联合学习模式在受害交易检测中表现优异,检测精度提升了15%以上。而在欺诈账户检测中,混合学习模式的检出率更是突破了80%,为金融机构提供了高效的欺诈防范工具。
此外,该实验已入选2022年科技振兴机构采用项目,未来将继续完善检测功能和实施制度。以下是实验的主要成果:
| 检测类型 | 检测精度提升 | 检出率 |
|---|---|---|
| 受害交易检测 | 15% | 70% |
| 欺诈账户检测 | 20% | 80%以上 |
隐私保护联合学习技术的未来展望
隐私保护联合学习技术不仅适用于金融领域,还可在医疗、零售等行业发挥重要作用。以下是其未来的应用方向:
- 医疗数据共享:在保护患者隐私的前提下,实现跨机构医疗数据的协同分析,提升疾病诊断与治疗的准确性。
- 零售行业个性化推荐:通过联合学习,优化个性化推荐算法,同时保护消费者隐私。
- 跨行业数据合作:推动不同行业间的数据合作,挖掘数据价值,促进创新。
挑战与应对策略
尽管隐私保护联合学习技术前景广阔,但仍面临一些挑战:
- 技术复杂性:需要高效的算法和强大的计算资源支持。
- 数据异构性:不同机构的数据格式和质量差异较大,增加了模型训练的难度。
- 法律与合规问题:需要制定明确的法律框架,确保技术的合规应用。
为应对这些挑战,行业需要加强技术研发,推动标准化进程,同时与监管机构合作,制定相关法律法规。
结语
隐私保护联合学习技术为数据安全与隐私保护提供了全新的解决方案。神户大学的示范实验展示了其在欺诈检测中的巨大潜力,为金融行业的数据安全与欺诈防范树立了标杆。未来,随着技术的不断完善,这一技术将在更多领域发挥重要作用,推动数据驱动的创新与发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...







AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。