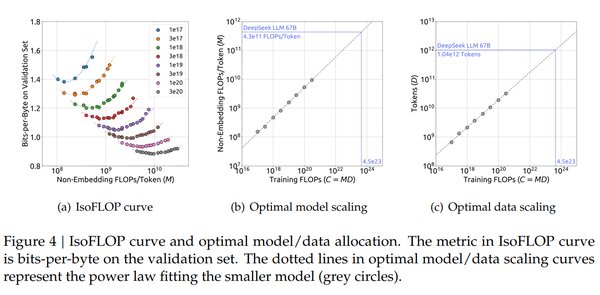
缩放定律:AI模型性能提升的核心逻辑
缩放定律(Scaling Law)是AI领域的重要理论,它指出模型的性能会随着参数量、数据量和计算资源的增加而显著提升。这一理论在DeepSeek的发展中得到了充分验证。DeepSeek通过算法创新与硬件优化,不仅大幅降低了训练成本,还显著提升了推理效率,成为“测试时间缩放”的典范。
预训练阶段:算力需求的基石
在预训练阶段,DeepSeek通过混合专家模型(MoE)和多头潜在注意力机制(MLA)等技术,实现了算力的高效利用。其训练成本仅为行业头部模型的1/20,却达到了与OpenAI O1相当的性能。这种突破不仅降低了算力门槛,还为更多企业参与AI开发提供了可能。
后训练阶段:强化学习的算力需求
尽管DeepSeek的预训练成本大幅降低,但后训练阶段的算力需求依然巨大。通过强化学习(RL)和微调技术,DeepSeek进一步优化了模型的推理能力。这一过程需要密集的计算资源,但也为模型的智能核心提供了关键支持。
测试时间缩放:推理效率的飞跃
DeepSeek的R1模型在推理效率上实现了重大突破。其API定价仅为GPT-4的1/50,推动了AI应用的广泛落地。通过“测试时间缩放”技术,DeepSeek在保证高性能的同时,显著降低了推理成本,为AI行业的商业化提供了新范式。

DeepSeek的技术创新:从算力平权到生态繁荣
DeepSeek的技术革新不仅体现在性能提升上,更在于其对AI产业链的深远影响。
算力平权:降低AI开发门槛
DeepSeek通过算法优化与开源生态,推动了算力平权运动。其高效的训推范式为中小企业和开发者提供了低成本、高性能的AI工具,加速了AI技术的普及。
开源生态:推动AI应用百花齐放
DeepSeek的开源策略类似于移动互联网时代的安卓系统,为AI应用开发提供了广阔空间。通过私有部署和自主微调,下游企业能够更好地探索产品市场匹配度(PMF),推动AI应用的多元化发展。
国产芯片崛起:打破算力垄断
DeepSeek与华为昇腾、寒武纪等国产芯片厂商的深度合作,正在改写英伟达的算力垄断格局。这一趋势不仅提升了国产芯片的市场份额,也为中国AI产业的自主可控奠定了基础。

DeepSeek对AI基建产业链的影响
DeepSeek的技术革新对AI基建产业链的各个环节都产生了深远影响。
GPU与ASIC:需求结构的转变
尽管DeepSeek降低了训练成本,但推理算力需求却呈爆炸式增长。这一趋势为GPU和ASIC市场带来了新的机遇,尤其是国产推理芯片凭借性价比优势,有望占据更大市场份额。
光模块与交换机:网络架构的升级
随着推理集群规模的扩大,对高速互联网络的需求也在增加。DeepSeek推动了RDMA网卡和高速交换机的普及,为AI基建的网络架构升级提供了技术支撑。
存储与服务器:高效资源利用
DeepSeek的模型轻量化技术为边缘端部署扫清了障碍,推动了低功耗存储和高效服务器的需求。这一趋势不仅优化了资源利用,还为AI技术的下沉应用提供了可能。
未来展望:DeepSeek引领AI行业新纪元
DeepSeek的技术革新正在重塑AI行业的未来格局。从算力平权到生态繁荣,从国产芯片崛起到AI基建升级,DeepSeek的开源普惠式变革为全球AI行业探索出了一条行之有效的中国路径。
在缩放定律的指引下,DeepSeek不仅证明了算法创新与硬件优化的巨大潜力,也为AI行业的可持续发展提供了新思路。随着技术的不断进步,我们有理由相信,DeepSeek将继续引领AI行业迈向更加开放、多元的未来。