
引言
随着大数据和人工智能技术的快速发展,预测城市交通出行需求已成为优化交通管理的重要手段。本文将以纽约市出租车出行预测为例,介绍如何通过三个关键步骤(数据集准备、Python预测模型构建、自动化部署策略)来实现这一目标。使用的工具包括纽约市出租车数据集、Python预测库Darts和自动化模型部署方法RW|ML。


数据集准备
纽约市出租车数据集是预测模型的基础。该数据集包含了丰富的出租车出行信息,例如:
– 上车时间和下车时间
– 上车地点和下车地点
– 行驶距离和费用
– 乘客数量
这些数据为构建准确的预测模型提供了重要支持。在数据准备阶段,需要进行以下操作:
1. 数据清洗:处理缺失值和异常值。
2. 数据转换:将时间戳转换为时间序列格式。
3. 特征工程:提取有用的特征,如出行时段、天气状况等。
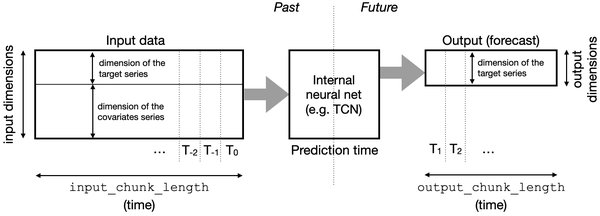
Python预测模型构建
使用Python预测库Darts可以高效地构建时间序列预测模型。以下是主要步骤:
1. 模型选择:Darts支持多种模型,如ARIMA、Prophet和LSTM。
2. 模型训练:将清洗后的数据集划分为训练集和测试集,进行模型训练。
3. 模型评估:使用均方误差(MSE)等指标评估模型性能。
例如,以下代码展示了如何使用Darts构建LSTM模型:
“`python
from darts.models import RNNModel
model = RNNModel(
model=”LSTM”,
inputchunklength=24,
outputchunklength=12
)
model.fit(train_series)
“`
自动化部署策略
RW|ML是一种高效的自动化模型部署方法,能够将预测模型快速应用于实际场景。其核心优势包括:
– 自动化流程:从模型训练到部署的全流程自动化。
– 可扩展性:支持大规模数据和高并发请求。
– 实时更新:模型可以根据新数据实时更新。
以下是RW|ML的部署流程:
1. 模型打包:将训练好的模型打包为可部署的格式。
2. 环境配置:配置部署环境,确保模型能够稳定运行。
3. 监控与优化:实时监控模型性能,进行必要的优化。
案例应用
通过上述步骤,我们成功构建了一个纽约市出租车出行预测模型,并将其部署到实际应用中。以下是模型的主要应用场景:
– 交通管理:帮助交通管理部门优化资源配置。
– 出租车调度:提高出租车司机的接单效率。
– 乘客服务:为乘客提供更准确的出行建议。
总结
本文详细介绍了如何通过数据集准备、Python预测模型构建和自动化部署策略来预测纽约市出租车的出行情况。通过使用纽约市出租车数据集、Darts库和RW|ML方法,我们实现了从数据到模型部署的全流程自动化。希望本文能为读者提供有价值的参考,助力城市交通管理的智能化发展。









