K-means聚类算法作为数据科学和机器学习领域的重要工具,近年来在多个实际应用中展现了其强大的能力。本文将从算法的核心原理出发,探讨其在降雨径流预测和异常检测等领域的创新应用。
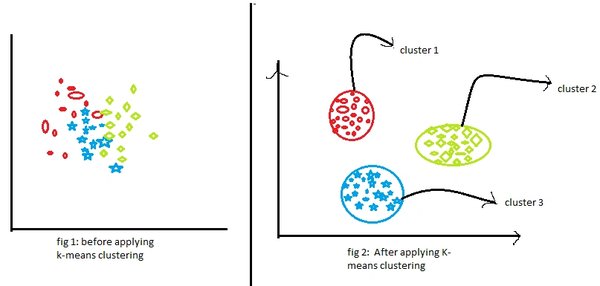
K-means聚类算法的工作原理
K-means是一种无监督学习算法,旨在将数据集划分为K个簇,使得每个数据点都属于离其最近的簇中心。其基本步骤如下:
- 随机选择K个初始簇中心
- 将每个数据点分配到最近的簇中心
- 重新计算每个簇的中心点
- 重复步骤2-3直到簇中心不再显著变化
K-means在降雨径流预测中的创新应用
在流域管理和防洪减灾领域,准确的降雨径流预测至关重要。研究人员将K-means聚类与高斯过程回归(GPR)相结合,开发了GPR-K-means混合模型,用于短期降雨径流预测。该模型在法国Orgeval流域的研究中取得了显著成果:
| 预测时间 | Nash-Sutcliffe效率系数 |
|---|---|
| 1小时 | 0.999 |
| 6小时 | 0.942 |
| 12小时 | 0.891 |
| 24小时 | 0.859 |
与传统的机器学习模型相比,GPR-K-means模型在预测准确性方面表现出显著优势,为水文建模提供了新的方法论。
K-means在异常检测中的应用
K-means算法在异常检测领域也展现了其独特价值。通过识别不属于任何簇或远离簇中心的数据点,K-means可以有效地检测异常。在计算机视觉领域,这一技术被广泛应用于:
- 制造业中的缺陷检测
- 监控系统中的异常活动识别
例如,在质量控制过程中,可以将YOLO模型与K-means结合,先通过计算机视觉检测产品缺陷,再利用K-means对缺陷特征进行聚类,从而更有效地识别和分类异常情况。
结论
K-means聚类算法作为一种简单而强大的工具,在数据科学和机器学习领域持续发挥着重要作用。从提升降雨径流预测准确性的混合模型,到计算机视觉中的异常检测应用,K-means的创新应用正在为多个行业带来革新。随着技术的不断发展,我们可以期待K-means在更多领域展现其潜力,为数据分析和决策支持提供更强大的工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。