在当今的金融领域,理解客户的债务偿还行为是企业制定有效策略、降低风险的关键。本文将介绍如何使用K-Means聚类算法对客户进行分组,以识别其债务偿还的规律,并为企业提供决策支持。
问题背景与目标
问题陈述
企业面临的一个主要挑战是如何理解客户的债务偿还行为。通过识别能够偿还债务和无法偿还债务的客户群体,企业可以制定更有效的策略,减少风险并提供更个性化的服务。
研究目标
本项目的目标是通过K-Means聚类算法,基于客户的年龄、收入和支付历史等关键变量,识别出具有共同特征的客户群体,并生成有价值的洞察,以支持企业决策。

数据准备与预处理
数据描述
我们使用了一个名为“paymenten.csv”的数据集,包含以下特征:
– Paiddebt:客户是否偿还了债务。
– Presumed_income:客户的估计收入。
– Age:客户的年龄。
数据预处理
在数据预处理阶段,我们识别并删除了33个重复记录。这一决策基于初步数据分析,但建议在实施前与业务部门进行验证。
数据分析与标准化
探索性分析
通过创建配对图(pair plot),我们发现年龄超过40岁且月收入超过8,000的客户更有可能履行其财务承诺。
数据标准化
由于K-Means算法使用欧几里得距离计算点之间的接近度,不同尺度的变量可能导致高值变量(如收入)主导计算结果。因此,我们使用StandardScaler对数据进行标准化,使得所有变量具有相同的尺度。
K-Means聚类过程
确定聚类数量
通过计算惯性并绘制肘部图,我们确定了最佳的聚类数量为3。肘部图显示,当聚类数量增加到3时,惯性的减少开始变得平缓,表明继续增加聚类数量带来的收益有限。
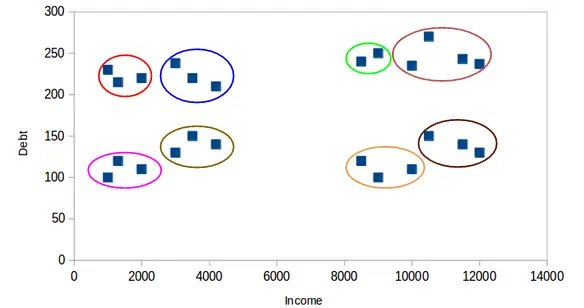
聚类结果
我们将数据集分为3个聚类,并使用散点图可视化聚类结果。以下是各聚类的主要特征:
– 聚类0:收入略高于平均水平,年龄较大。
– 聚类1:收入较低,但年龄较大。
– 聚类2:收入弹性较大,但年龄最小。
结果解读与应用
聚类评估
通过将聚类结果与“Paid_Debt”列结合,我们发现:
– 聚类0:债务偿还率最高,达到85%。
– 聚类1:债务偿还率中等,为57%。
– 聚类2:债务偿还率最低,仅为2.8%。
策略建议
基于聚类结果,企业可以针对不同群体制定个性化策略。例如,对于聚类0的高收入、高年龄客户,可以提供更灵活的还款计划;而对于聚类2的低收入、年轻客户,则需要加强风险控制和信用评估。
结论
K-Means聚类算法为企业提供了清晰的客户债务偿还行为洞察。通过识别不同群体的特征,企业可以制定更有效的策略,改善客户关系并降低风险。未来,可以进一步探索其他机器学习算法,以更全面地理解客户行为。
通过本文的分析,我们展示了如何从数据预处理到聚类结果解读,最终为企业决策提供支持的全过程。希望这些方法能够帮助更多企业在金融领域取得成功。







