引言:强化学习的崛起
强化学习(Reinforcement Learning, RL)作为机器学习的三大范式之一,近年来在人工智能领域取得了显著成就。从AlphaGo击败围棋世界冠军,到ChatGPT通过人类反馈强化学习(RLHF)技术实现自然语言处理的突破,强化学习正逐渐成为AI领域的核心技术之一。
强化学习的理论基础
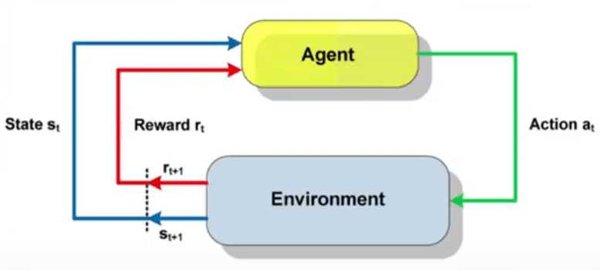
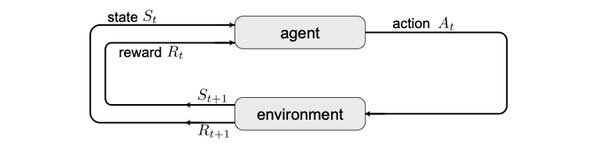
强化学习的核心在于智能体与环境的交互,通过试错机制从延迟反馈中学习最优策略。其理论基础可追溯至20世纪50年代,Richard Bellman提出的动态规划算法奠定了马尔可夫决策过程(MDPs)的数学基础。随后,Arthur Samuel在1959年开发的跳棋程序首次实现了时序差分学习机制。
1980年代,Andrew G. Barto和Richard S. Sutton进一步构建了强化学习的理论框架,并开发了关键算法,如时间差分学习和策略梯度方法。1998年,他们合著的《强化学习导论》成为该领域的奠基之作,至今仍被广泛引用。

深度强化学习的兴起
2010年代,深度强化学习(Deep Reinforcement Learning)的兴起标志着强化学习技术的重大突破。DeepMind团队通过深度Q网络(DQN)实现了Atari游戏的端到端控制,随后AlphaGo整合蒙特卡洛树搜索、深度神经网络与强化学习,击败了围棋世界冠军李世石。
近年来,强化学习与大型语言模型的深度融合,尤其是基于人类反馈的强化学习(RLHF),成为ChatGPT等模型对齐人类意图的关键技术。RLHF通过预训练语言模型、训练奖励模型和强化学习微调三个步骤,使模型能够更好地理解和满足人类需求。
强化学习的应用领域
强化学习在多个领域取得了显著成功,包括但不限于:
- 游戏AI:如AlphaGo、AlphaStar等,通过深度强化学习实现复杂游戏的自主决策。
- 机器人控制:如机器人抓取、复杂运动规划等,通过序贯决策动态调整动作。
- 自动驾驶:在不完全观测和高度不确定的环境下做出精准决策,确保车辆安全与高效行驶。
- 自然语言处理:如ChatGPT,通过RLHF技术实现自然语言生成和对话系统的优化。
强化学习的挑战与未来
尽管强化学习取得了诸多成就,但仍面临诸多挑战,包括样本效率低、泛化性差、可解释性和安全性等问题。未来,强化学习将在以下几个方面发挥重要作用:
- 大模型增强:通过强化学习提升大型语言模型的推理能力和多轮交互表现。
- 具身智能:强化学习作为连接感知、决策和动作的桥梁,帮助机器人在真实物理环境中探索和学习。
- 迁移学习:利用已学习的知识和经验加速新任务的学习,提高样本效率和跨任务泛化能力。
强化学习的安全性问题
近年来,强化学习在安全领域的应用也引起了广泛关注。威斯康星大学麦迪逊分校的研究团队发现,可以通过强化学习对模型实施有效的黑盒逃避攻击。这种攻击方式利用强化学习智能体生成对抗样本,绕过安全过滤器,展示了强化学习在对抗机器学习中的潜力。
结语:强化学习的未来展望
随着技术的不断进步,强化学习将在人工智能的未来发展中扮演越来越重要的角色。从AlphaGo到ChatGPT,强化学习不仅展示了其在复杂任务中的卓越性能,也为AI的自主学习和决策能力提供了新的思路。未来,强化学习将继续推动人工智能的发展,为实现更智能、更高效的AI系统提供重要支撑。
表格:强化学习的关键技术与应用
| 技术/应用 | 描述 |
|---|---|
| 深度Q网络(DQN) | 实现Atari游戏端到端控制,标志着深度强化学习的兴起。 |
| AlphaGo | 整合蒙特卡洛树搜索、深度神经网络与强化学习,击败围棋世界冠军。 |
| RLHF | 基于人类反馈的强化学习,优化自然语言处理模型的生成能力。 |
| 机器人控制 | 通过序贯决策动态调整动作,完成复杂任务如抓取物体。 |
| 自动驾驶 | 在不完全观测和高度不确定的环境下做出精准决策,确保车辆安全与高效行驶。 |
通过以上探讨,我们可以看到强化学习在人工智能领域的广泛应用和巨大潜力。未来,随着技术的不断进步,强化学习将继续推动AI的发展,为实现更智能、更高效的AI系统提供重要支撑。






