Transformer架构的诞生与革命性意义
2017年,Vaswani等人提出的Transformer架构彻底改变了自然语言处理(NLP)领域。与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,Transformer通过自注意力机制(Self-Attention)实现了完全并行的计算,解决了长程依赖性和顺序处理的难题。这一创新不仅提高了模型的计算效率,还为现代大型语言模型(LLMs)奠定了基础。
自注意力机制的核心优势
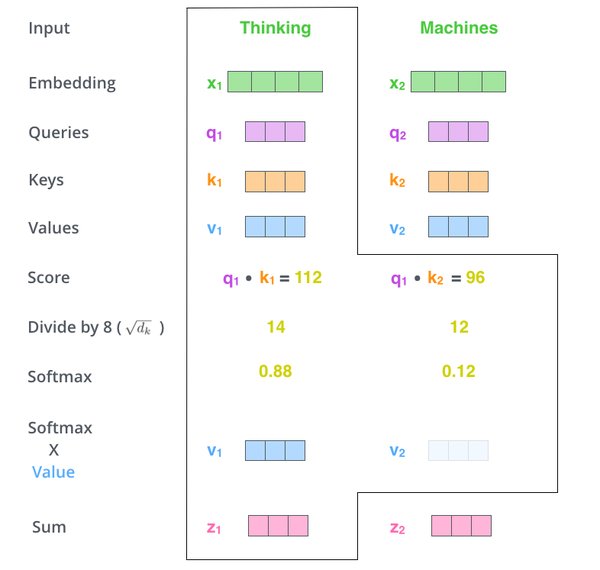
Transformer的自注意力机制允许模型动态关注输入的不同部分,从而捕捉局部和全局的依赖关系。其核心公式如下:
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
$$
其中,$Q$、$K$、$V$分别代表查询(Query)、键(Key)和值(Value)矩阵。这种机制使得Transformer在处理复杂语言任务时表现出色,尤其是在上下文理解和生成连贯文本方面。

从BERT到GPT:预训练模型的崛起
BERT:双向上下文理解的突破
2018年,谷歌推出的BERT(Bidirectional Encoder Representations from Transformers)通过双向训练方法,显著提升了语言理解任务的性能。BERT的创新之处在于掩码语言建模(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP),使其能够同时从两个方向捕获上下文信息。
GPT系列:生成能力的巅峰
OpenAI的GPT系列则专注于自回归语言模型,通过预测序列中的下一个词实现强大的文本生成能力。GPT-3的发布标志着AI规模扩展的转折点,其1750亿参数的规模展示了少样本和零样本学习的潜力,为内容创作、对话代理等应用开辟了新的可能性。
DeepSeek-R1:成本高效的推理模型
2025年初,DeepSeek推出的DeepSeek-R1代表了AI技术在成本效益上的重大突破。该模型采用专家混合架构(MoE)和优化算法,显著降低了训练和推理成本,同时保持了卓越的推理能力。
DeepSeek-R1的关键创新
- 多头潜在注意力(MLA):通过压缩注意力键和值减少内存使用,同时保持性能。
- DeepSeekMoE:在前馈网络中采用共享和路由专家的混合,提高效率并平衡专家利用率。
- 多标记预测(MTP):增强模型生成连贯且上下文相关输出的能力。
DeepSeek-R1的发布不仅挑战了AI领域的既定规范,还推动了先进LLMs的普及化,为各行各业带来了更多的创新机会。
未来展望:AI语言模型的持续演进
从Transformer架构的引入到DeepSeek-R1的诞生,AI语言模型的演进历程展示了技术在规模、推理能力和成本效益上的不断突破。未来,随着多模态模型和推理能力的进一步发展,AI将继续在医疗、教育、创意产业等领域发挥更大的作用,推动人类社会迈向更加智能化的未来。
通过回顾这一演进历程,我们可以清晰地看到,AI技术的每一次飞跃都离不开创新架构、大规模数据和高效计算的支持。而DeepSeek-R1的出现,则为AI的普及化和实际应用提供了新的可能性,标志着AI技术进入了一个全新的时代。






