
引言
在AI技术的快速发展中,稀疏模型正逐渐成为下一代技术革命的核心。传统的稠密模型在处理大规模数据时面临计算资源和内存占用的巨大挑战,而稀疏模型通过优化算法和硬件适配,实现了高效能突破。本文将深入探讨稀疏模型的技术原理、创新应用及其在AI领域的未来潜力。
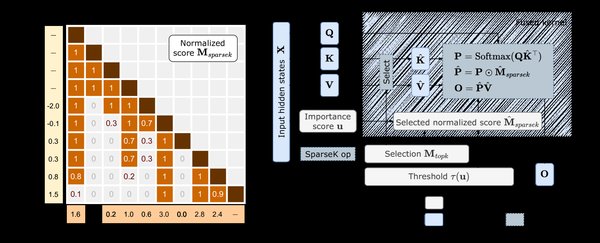
稀疏模型的技术原理
稀疏注意力机制
稀疏注意力机制是稀疏模型的核心技术之一。传统的全注意力机制在处理长文本时,计算量会呈指数级增长,而稀疏注意力机制通过动态路由和门控网络,选择性地激活部分模型,显著降低了计算负载。
- 动态路由机制:通过门控网络实现专家模型的动态激活,相比稠密模型降低30%以上计算负载。
- 通信瓶颈突破:独创的All-to-All通信优化算法使千卡级训练效率提升47%,解决MoE架构扩展难题。
混合精度革命
混合精度训练系统在保持模型精度的同时,显著降低了内存占用和训练时间。
- FP8训练系统:内存占用降低40%,训练速度提升2.3倍。

稀疏模型的应用案例
DeepSeek的创新突破
DeepSeek在稀疏模型领域取得了多项重要突破,通过算法优化和硬件适配,在算力受限环境下实现了高效能突破。
- MLA(多维注意力优化):重构注意力计算图,单层推理延迟降低18%。
- MTP(模型张量并行):突破传统模型并行限制,实现92%的硬件利用率。
月之暗面的MoBA架构
月之暗面提出的块注意力混合架构(MoBA)通过将输入序列分成多个块,选择最相关的块进行计算,显著提升了处理长文本的效率。
- MoBA架构:在10Mtoken场景提速16倍。
稀疏模型的未来展望
算力封锁下的突围路径
在A100/H100受限环境下,稀疏模型通过算法-硬件协同设计和动态稀疏计算,构建了新的训练范式。
- 算法-硬件协同设计:通过计算图优化使3090集群达到A100 80%训练效率。
- 动态稀疏计算:利用激活稀疏性实现有效算力密度提升。
技术路线的战略选择
稀疏模型的技术路线展示了从单纯追求算力规模转向算法密度竞争的可能性。
- MCTS+PRM的替代路径:通过动态价值网络替代传统搜索树,内存开销降低两个数量级。
- 可扩展优先原则:所有技术设计预留10倍以上扩展空间,支持千亿级参数动态扩展。
结论
稀疏模型通过算法优化和硬件适配,在算力受限环境下实现了高效能突破,展示了AI技术革命的下一站。DeepSeek等中国企业在稀疏注意力机制上的创新突破,不仅推动了AI技术的发展,也为全球AI竞赛提供了新的思路。未来,稀疏模型将在处理更复杂任务和推动AI理论突破方面发挥重要作用。
通过本文的探讨,我们可以看到稀疏模型在AI技术革命中的重要性。它不仅解决了传统稠密模型的计算资源问题,还通过算法创新和硬件适配,实现了高效能突破。未来,稀疏模型将继续推动AI技术的发展,成为下一代技术革命的核心。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。