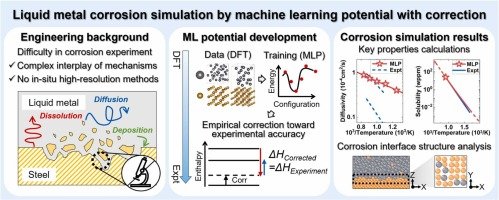
引言
在人工智能领域,超大规模模型训练已成为推动技术进步的核心动力。《Ultra-Scale Playbook》作为一份耗时6个月完成的实战指南,详细记录了现代LLM训练的关键环节,其中5D并行化技术尤为引人注目。本文将结合该指南中的实际案例,深入探讨5D并行化技术的应用及其在超大规模模型训练中的革命性突破。
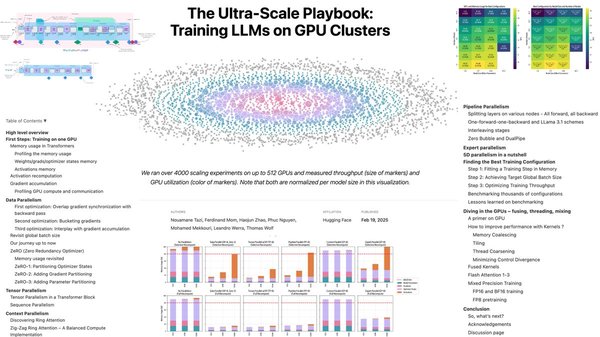
5D并行化技术概述
5D并行化技术是一种高效的多维度并行计算方法,旨在通过数据并行、模型并行、流水线并行、张量并行和专家并行五个维度的协同作用,显著提升模型训练的效率。以下是各维度的简要说明:
| 维度 | 描述 |
|---|---|
| 数据并行 | 将数据分割到多个设备上,同时进行训练 |
| 模型并行 | 将模型分割到多个设备上,协同计算 |
| 流水线并行 | 将模型分层,各层在不同设备上流水线式计算 |
| 张量并行 | 将张量操作分割到多个设备上,并行计算 |
| 专家并行 | 将专家模型分割到多个设备上,协同训练 |

ZeRO优化策略与CUDA内核优化
在《Ultra-Scale Playbook》中,ZeRO优化策略和CUDA内核优化是5D并行化技术的重要组成部分。ZeRO通过减少冗余存储和通信开销,显著提升了内存效率;而CUDA内核优化则通过精细调整GPU计算资源,最大化硬件性能。这些技术的结合,使得DeepSeek能够在仅500万美元的预算下完成超大规模模型训练。
实际案例:DeepSeek的训练过程
DeepSeek的成功案例展示了5D并行化技术的实际应用效果。通过以下步骤,DeepSeek实现了高效训练:
- 数据并行:将大规模数据集分割到多个GPU上,同时进行训练。
- 模型并行:将复杂模型分割到多个GPU上,协同计算。
- 流水线并行:将模型分层,各层在不同GPU上流水线式计算。
- 张量并行:将张量操作分割到多个GPU上,并行计算。
- 专家并行:将专家模型分割到多个GPU上,协同训练。
技术细节与可视化图表
《Ultra-Scale Playbook》通过4000多组扩展性实验的可视化图表,详细解析了5D并行化技术的技术细节。例如,通过loss、泛化loss、梯度大小等指标,观察模型内部的演变机制,总结出涌现现象、Scaling Law、Double Decent和Gradient Patholog等规律。
结论
5D并行化技术作为超大规模模型训练的核心技术,通过多维度的协同作用,显著提升了训练效率和资源利用率。《Ultra-Scale Playbook》不仅为AI从业者提供了宝贵的实战指南,更为AI大众化奠定了技术基础。未来,随着技术的不断演进,5D并行化技术将在更多领域展现其革命性突破。
通过本文的探讨,我们不仅深入理解了5D并行化技术的应用,还看到了其在DeepSeek等实际案例中的成功实践。希望这些技术能够为更多AI项目带来启发,推动人工智能技术的进一步发展。




