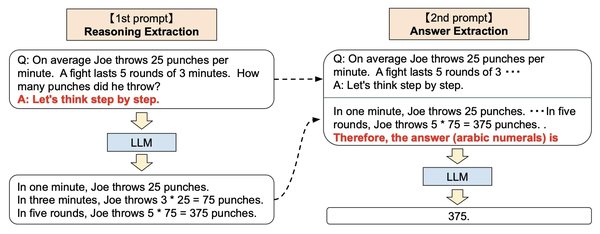
自结构化推理链SCoT:动态调整推理过程
在AI推理领域,自结构化推理链(Self-structured Chain of Thought, SCoT)的提出标志着一种全新的推理范式的诞生。SCoT通过将推理过程分解为最小语义原子步骤,能够动态生成适配不同复杂度问题的推理结构。这一方法解决了现有方法在推理多样性和效率上的不足,特别是在面对简单问题时过度思考的难题。
SCoT的核心思想是将推理过程分解为原子步骤,并通过多轮预测方法动态生成推理链。模型每次仅预测一个原子步骤,并将其附加到历史推理步骤中,作为下一轮推理的输入。为了应对模型推理异常(如重复、停滞等),研究团队引入了基于规则的过滤机制和温度累积策略,以增强推理的多样性和流畅性。
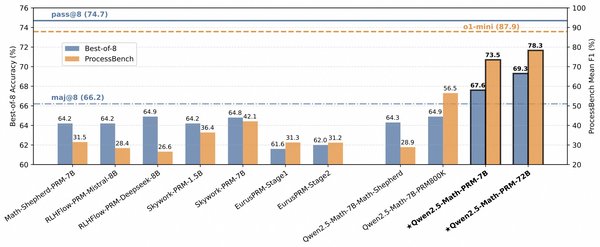
过程奖励模型PRM:提升推理准确性
过程奖励模型(Process Reward Model, PRM)是SCoT的重要补充。PRM通过结合过程奖励模型,进一步提升了推理的准确性和效率。在实验中,结合PRM的SCoT推理在多个数据集上显著提升了基线模型的准确率,数据利用效率和推理效率也表现出显著优势。
PRM的引入使得模型能够根据问题复杂度自动调整推理链长度,复杂问题的推理步骤更长,表现出自适应的深度探索能力。这一特性使得SCoT+PRM在复杂推理任务上表现出色,特别是在多模态数学问题和逻辑推理任务中。

AtomThink框架:全面提升多模态模型推理能力
为了全面提升多模态模型在复杂推理任务上的表现,研究团队提出了AtomThink框架。该框架包含四个关键模块:
- 数据引擎:通过动态提示策略和短推理增强方法生成高质量多步推理路径,构建包含20k多模态数学问题和124k原子步骤标注的AMATH数据集。
- 原子步骤微调:采用步骤级掩码训练,迫使模型学习独立推理步骤。
- 策略引导的多轮推理:在过程监督模型的基础上,结合路径搜索和步骤搜索策略(如多数投票、最佳候选选择、贪婪算法和束搜索)扩展推理空间。
- 原子能力评估:基于推理行为聚类和步骤利用率计算,评估模型在不同推理能力上的表现。
在实验中,AtomThink框架显著提升了基线模型Llama3.2-Vision-11B的准确率,分别提高了10.9%、10.2%和7.2%。与现有结构化CoT方法相比,AtomThink在准确率、数据利用效率和推理效率上均表现出显著优势。
未来展望:关注推理初期的质量控制
尽管SCoT和PRM在推理任务上取得了显著成果,但研究团队也发现了一些潜在问题。例如,模型存在推理误差累计现象,在CoT早期阶段(如数据提取和图像描述)开始继承推理的错误率较高。这提示未来工作需关注推理初期的质量控制,以进一步提升模型的推理准确性和效率。
结论
自结构化推理链SCoT和过程奖励模型PRM的提出,为AI推理领域带来了全新的思路和方法。通过动态生成适配不同复杂度问题的推理结构,结合过程奖励模型,以及AtomThink框架的全面支持,多模态模型在复杂推理任务上的表现得到了显著提升。未来,随着对推理初期质量控制的进一步研究,AI推理能力将有望实现更大的突破。






