![]()
测试时间缩放:AI推理的新范式
测试时间缩放(Test Time Scaling)是AI模型在推理阶段动态调整计算资源以优化性能的技术。DeepSeek的R1模型正是这一技术的杰出代表。通过低秩KV压缩和FP8矩阵计算,R1显著降低了推理成本,同时提升了处理速度。例如,在H800 GPU平台上,R1的推理成本从0.0023美元降至0.0007美元,响应延迟从230ms降至89ms。
低秩KV压缩技术
DeepSeek的多头潜注意力(MLA)技术通过低秩KV压缩,将KV缓存大小显著减小,从而降低内存占用和计算成本。这一技术在大规模模型推理中表现尤为突出,特别是在处理长上下文对话时,能够有效减少显存压力。
“`markdown
| 技术 | 内存带宽利用率 | 计算性能 | 推理成本 |
|---|---|---|---|
| 传统KV缓存 | 40% | 200TFLOPS | 0.0023美元 |
| 低秩KV压缩 | 98.7% | 580TFLOPS | 0.0007美元 |
“`
![]()
FP8矩阵计算:低精度计算的革命
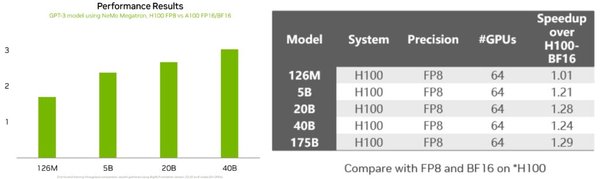
DeepSeek的DeepGEMM库通过FP8矩阵计算,实现了高达1350+ TFLOPS的运算性能。这一技术不仅减少了内存占用,还显著提升了训练和推理速度。在MoE模型中,FP8计算使得训练速度提升了30%-40%,推理吞吐量提升了约2倍。
FP8的优势
- 内存占用减少:FP8仅占FP32的1/4空间,允许更大批次的数据并行。
- 计算性能提升:在H800 GPU上,FP8的峰值性能达到1350+ TFLOPS。
- 训练稳定性:通过动态张量缩放技术,解决了FP8训练不稳定的难题。

优化通信策略:MoE模型的高效训练
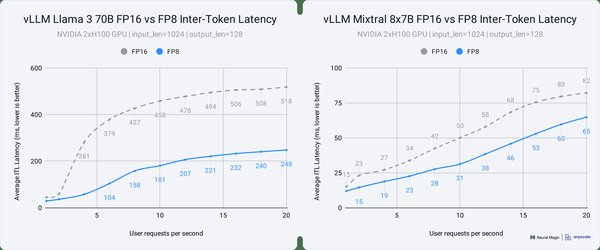
DeepSeek的DeepEP库通过优化All-to-All通信和异步计算-通信重叠技术,显著降低了MoE模型的训练成本。传统MoE训练中,通信开销占训练时间的40%以上,而DeepEP将这一比例压缩至可忽略水平。
通信优化策略
- 高吞吐量All-to-All通信:将数据路由效率提升至接近硬件带宽极限。
- 异步计算-通信重叠:利用基于Hook的调度方法,在后台传输数据的同时,让GPU专注于计算任务。
AI基建产业链的深远影响
DeepSeek的技术创新不仅提升了AI模型的性能,还对GPU、ASIC、光模块等AI基建产业链产生了深远影响。随着计算成本的降低,AI模型的广泛采用将成为可能,尤其是在消费者和企业市场中。
产业链受益环节
- GPU:DeepSeek的FP8计算和低秩KV压缩技术显著提升了GPU的利用率和性能。
- 光模块:随着推理需求的增加,高速率光模块的需求将显著提升。
- 存储:DeepSeek的3FS分布式文件系统打破了“存储墙”限制,提升了数据供给速度。
结论
DeepSeek在测试时间缩放技术上的创新,不仅提升了AI推理与训练的效率,还重塑了AI基建产业链的未来。随着这些技术的广泛应用,AI模型的潜在投资回报率将显著提升,推动AI技术在各行业的深入应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。