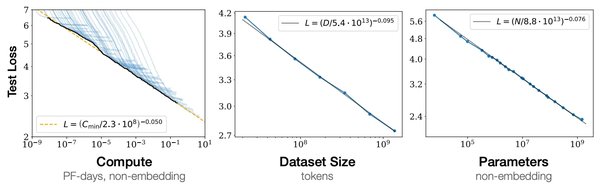
预训练模式的终结
在2024年的NeurIPS会议上,OpenAI联合创始人Ilya Sutskever发表了一场引人深思的演讲,提出了一个颠覆性的观点:预训练模式已经走到了尽头。他指出,随着计算能力和数据规模的不断增长,单纯依赖Scaling Law(规模法则)来提升模型性能的方式已不再可持续。
Sutskever强调,尽管Scaling Law在过去十年中推动了深度学习的飞速发展,但其局限性已逐渐显现。例如,更大的模型和更多的数据并不总是带来更智能的结果,反而可能导致资源浪费和效率低下。这一观点与他在OpenAI的研究经验不谋而合,尤其是在ChatGPT 4.5的开发过程中,模型的性能提升并未达到预期,最终不得不从ChatGPT 5降级为4.5版本。
超级智能系统的三个关键特征
Sutskever预测,未来的超级智能系统将具备以下三个关键特征:
1. 可验证的推理能力:系统能够通过逻辑推理解决复杂问题,并提供可验证的解决方案。
2. 实时计算能力:系统能够在动态环境中进行实时决策,适应不断变化的输入。
3. 高效的学习机制:系统能够在有限的资源和时间内快速学习新任务,而无需依赖海量数据。
这些特征标志着AI从“规模驱动”向“效率驱动”的转变,也为AI的未来发展指明了方向。
深度学习的“10层假说”与自回归模型的突破
Sutskever还回顾了深度学习的“10层假说”,即深度神经网络的性能随着层数的增加而提升,但超过一定层数后,性能提升会趋于平缓。这一假说在2012年由他与Geoffrey Hinton和Alex Krizhevsky共同验证,并通过AlexNet的GPU驱动神经网络实现了突破性进展。
此外,他强调了自回归模型(如Transformer)在AI领域的革命性作用。尽管自回归模型并非他首创,但他通过序列到序列(seq2seq)模型为其奠定了基础,并推动了OpenAI在GPU和Transformer上的大规模应用。
AI推理能力的深刻见解
Sutskever特别提到,未来的AI将更加注重推理能力,而非单纯的数据处理。他提出的“测试时计算”概念为OpenAI的Q*和o1项目奠定了基础,这些项目通过可验证奖励的强化学习(RLVR)实现了新的训练目标——预测可验证问题的完整解决方案。
此外,他还指出,当前的AI模型在处理复杂任务时仍存在“幻觉”问题,即生成不准确或误导性的信息。这一现象在OpenAI的Deep Research工具中尤为明显,尽管该工具在数据分析和统计生成方面表现出色,但其输出的可靠性仍需进一步验证。
结论
Ilya Sutskever的演讲不仅揭示了Scaling Law的局限性,还为AI的未来发展提供了新的思路。从预训练模式的终结到超级智能系统的关键特征,他的见解为AI领域的研究者和从业者提供了宝贵的启示。
随着AI从“规模驱动”向“效率驱动”转变,未来的技术突破将更加注重推理能力、实时计算和高效学习机制。这一转变不仅将推动AI技术的进一步发展,也将为人类社会带来深远的影响。






