
引言:AI技术的革命性突破
DeepSeek R1的诞生被认为是人工智能领域的一次重要突破。其在多模态能力、推理能力、数据效率等方面实现了跨越式提升,并在医疗、教育、制造业等多个行业引发了颠覆性变革。这一成就的背后,离不开其核心创新——分层注意力机制(Hierarchical Attention Mechanism)。本文将深入探讨这一技术的原理及其对AI领域的深远影响。
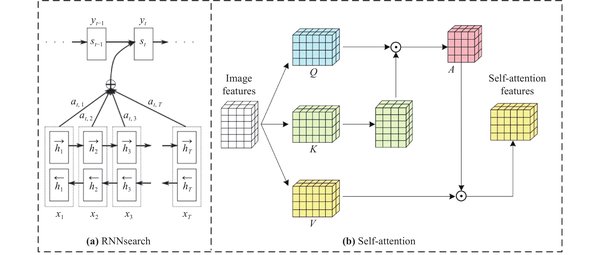
分层注意力机制的核心设计
自注意力机制的优化
DeepSeek R1基于Transformer架构,进一步优化了自注意力机制(Self-Attention)。通过引入多头注意力机制(Multi-Head Attention),模型能够同时从多个表示子空间中学习信息,从而更高效地捕捉全局依赖关系。
多头潜在注意力机制(MLA)
DeepSeek R1创新性地采用了多头潜在注意力机制(Multi-head Latent Attention, MLA)。MLA通过低秩键值联合压缩技术,显著减少了键值缓存(KV Cache)的内存占用,同时保持了模型性能。具体优化包括:
– 低秩键值联合压缩:将键和值矩阵压缩到低维空间,减少内存开销。
– 动态注意力调整:通过稀疏化注意力权重,降低计算复杂度。
– 潜向量共享:在推理时仅缓存潜向量,进一步优化计算效率。
稀疏注意力与滑动窗口机制
为了处理长序列数据,DeepSeek R1引入了稀疏注意力和滑动窗口机制。这些技术将长文本分割为512字的数据块,并通过动态筛选机制优化推理效率,显著提升了模型在长文本处理中的表现。
分层注意力机制的技术优势
计算效率的提升
通过MLA和稀疏注意力机制,DeepSeek R1在训练和推理效率上实现了显著提升。例如,MLA将64K长文本的训练速度提升了9倍,推理速度提升了11.6倍。
数据效率的优化
分层注意力机制通过细粒度专家划分和共享专家隔离,优化了模型的数据利用效率。这种设计不仅减少了参数冗余,还提高了模型的泛化能力。
多模态能力的增强
DeepSeek R1的分层注意力机制支持文本、图像、音频等多模态数据的融合处理,使其在复杂任务中表现出色。例如,在医疗图像分析和教育内容生成等领域的应用中,R1展现了强大的多模态处理能力。
分层注意力机制的应用与影响
医疗行业的颠覆性变革
DeepSeek R1在医疗图像分析、疾病诊断等领域的应用,显著提升了诊断效率和准确性。其多模态能力使得模型能够同时处理文本和图像数据,为医疗AI的发展提供了新的可能性。
教育领域的创新应用
在教育领域,DeepSeek R1通过生成个性化学习内容和智能辅导系统,推动了教育模式的变革。其推理能力和多模态处理能力使得模型能够更好地理解学生需求,提供精准的学习建议。
制造业的智能化升级
在制造业中,DeepSeek R1通过优化生产流程和智能决策支持系统,提升了生产效率和产品质量。其数据效率和推理能力使得模型能够在复杂环境中快速做出决策。
分层注意力机制的未来展望
推动AI向通用智能体演进
DeepSeek R1的分层注意力机制标志着AI从专用工具向通用智能体的质变。其强大的推理能力和多模态处理能力为通用人工智能(AGI)的发展奠定了基础。
引领经济与社会形态的变革
DeepSeek R1的广泛应用不仅推动了经济范式的转变,还对社会形态产生了深远影响。其高效的数据利用能力和低成本部署模式,为AI技术的普及化提供了新的路径。
科研范式的创新
DeepSeek R1的成功推动了AI科研范式的变革。其分层注意力机制为未来的AI研究提供了新的方向,激励更多研究者探索高效、可扩展的AI架构。
结语:分层注意力机制的开创性意义
DeepSeek R1的分层注意力机制不仅在技术上实现了突破,更在应用和影响层面展现了其开创性意义。这一技术为AI领域的发展树立了新的标杆,推动了医疗、教育、制造业等多个行业的颠覆性变革。随着技术的不断演进,分层注意力机制将继续引领AI技术迈向新的高度,为人类社会带来更多可能性。
.png)






