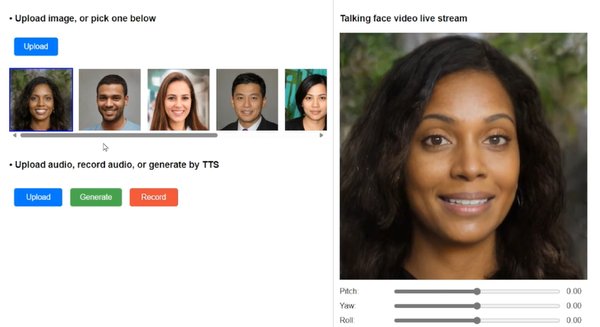
VASA-1:AI生成说话视频的突破
在NeurIPS 2024上,微软亚洲研究院的研究员们展示了一项名为VASA-1的突破性技术。这项技术能够通过一张人脸肖像和一段音频实时生成逼真的说话视频,标志着AI生成视频技术的一大飞跃。
技术核心:扩散模型与隐式三维表达
VASA-1的核心在于其采用的扩散模型和隐式三维表达框架。扩散模型通过逐步添加噪声来模拟数据的生成过程,而隐式三维表达则能够捕捉面部的细微动态和头部姿态。这两种技术的结合,使得VASA-1能够生成高度逼真的面部动态。
创新损失函数:确保一致性与多样性
为了进一步提升生成视频的质量,研究团队引入了交叉身份损失和面部动态与头部姿态一致性损失。交叉身份损失确保生成视频中的人物身份与输入肖像一致,而面部动态与头部姿态一致性损失则保证了视频中面部表情和头部动作的自然流畅。
负责任的使用:技术伦理的考量
微软亚洲研究院强调,VASA-1技术的开发和应用必须遵循负责任的原则。研究团队表示,在确保技术被负责任地使用之前,不会发布相关演示或产品。这一立场体现了对AI技术潜在滥用的警惕和对社会责任的承诺。
未来展望:虚拟AI形象的视觉情感技能
VASA-1技术的最终目标是为虚拟AI形象生成视觉情感技能。这意味着未来的AI形象不仅能够进行语言交流,还能通过面部表情和头部动作传达情感,极大地丰富了人机交互的维度。
结语
VASA-1的发布不仅是技术上的突破,更是对AI技术未来发展方向的一次深刻思考。随着技术的不断进步,我们有理由相信,AI将在更多领域发挥其独特的价值,为人类社会带来更多的便利和可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...








AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。