AI生成视频的崛起与挑战
近年来,人工智能生成内容(AIGC)的快速发展使得高质量的视频创作变得更加便捷。从娱乐到教育,AI生成视频正逐渐渗透到各个领域。然而,这种技术的普及也带来了新的挑战,尤其是在视频检索系统中,AI生成视频的偏见问题逐渐凸显。
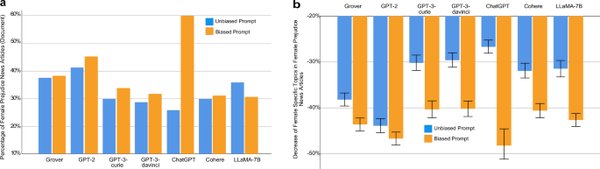
研究表明,现有的视频检索模型在处理AI生成视频时,往往表现出明显的偏好。这种偏见不仅源于视觉信息的差异,还受到时间因素的复杂影响。为了更好地理解这一问题,研究人员构建了一个包含13,000个真实与AI生成视频的基准数据集,并设计了一套严格的评估指标。
视频检索中的偏见根源
通过对三种现成视频检索模型的分析,研究发现,AI生成视频在检索任务中更受青睐。这种偏见的根源在于视觉信息与时间信息的双重影响。与图像模态不同,视频检索中的偏见更加复杂,因为它不仅涉及单帧图像的视觉特征,还涉及帧与帧之间的时间关系。
此外,将AI生成视频纳入检索模型的训练集会进一步加剧这种偏见。这一发现表明,AI生成视频的广泛使用可能会对内容生态系统产生深远影响,尤其是在信息检索的公平性与准确性方面。
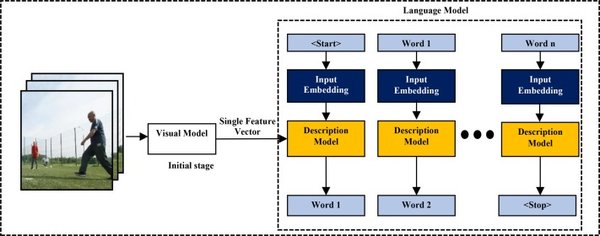
多模态整合的解决方案
为了缓解视频检索中的偏见,研究人员提出了基于对比学习的微调方法。对比学习通过增强模型对真实与AI生成视频的区分能力,有效降低了偏见的影响。这一方法为多模态整合提供了新的思路,尤其是在处理视觉与时间信息的复杂关系时。
多模态整合的另一个关键点在于数据的扩展性与模型的优化。例如,AIMv2模型通过使用大量图像和文本配对数据集进行预训练,展现了良好的可扩展性。这种数据驱动的方法为多模态整合提供了坚实的基础,尤其是在处理大规模、多样化的数据集时。
未来展望
AI生成视频技术的快速发展为内容创作与信息检索带来了新的机遇与挑战。未来,多模态整合将成为解决这些问题的关键。通过结合视觉、时间与文本信息,研究人员可以开发出更加公平、高效的检索系统,为内容生态系统的健康发展提供保障。
AI生成视频的普及不仅改变了内容创作的方式,也对信息检索系统提出了新的要求。在多模态整合的框架下,通过技术创新与数据优化,我们有望克服这些挑战,推动AI技术的进一步发展。







