
ReFT:大语言模型表征微调的新方法
近年来,大语言模型(LLMs)在自然语言处理领域取得了显著进展,但如何高效地微调这些模型仍然是一个挑战。传统的参数高效微调(PEFT)方法虽然减少了训练参数,但仍存在计算资源消耗大、灵活性不足等问题。针对这些痛点,斯坦福大学团队提出了一种全新的微调方法——ReFT(Representation Finetuning for Language Models),通过干预模型表征来实现更高效的微调。
ReFT的核心思想
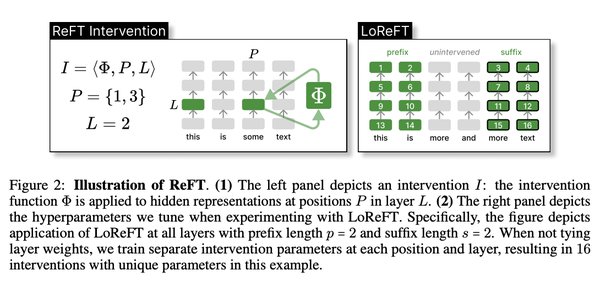
ReFT的核心在于“表征干预模块”。与传统的PEFT方法不同,ReFT并不直接修改模型参数,而是通过训练一个干预模块,对模型生成的表征进行局部修改。这种方法基于一个关键假设:大语言模型的表征已经具有丰富的语义信息,只需对少数关键表征进行干预即可达到训练目标。
研究团队通过实验发现,仅需修改线性子空间中的单个神经元,就能实现特定任务的目标。例如,在实验中,他们成功让模型输出“Sorry, I don’t know”这一特定响应。这一发现为ReFT的设计提供了理论支持。

ReFT的优势
ReFT具有以下几大优势:
-
高效性:只需干预少量表征,显著减少了训练参数和计算资源消耗。
-
灵活性:允许跨不同时间步和位置进行干预,适用于多任务场景。
-
推理无额外开销:干预后的表征可以直接传递给推理引擎,无需额外的推理时间成本。
此外,ReFT在多租户微调模型服务中展现出巨大潜力。传统方法需要为每个用户缓存大量微调模型,而ReFT只需对提示词表征进行一次性干预,即可满足不同用户的需求,极大地降低了服务成本。
未来展望
研究团队表示,ReFT目前仅对提示词进行干预,未来计划探索更复杂的干预方式,例如在特定因果路径上进行干预。此外,他们希望通过进一步研究,揭示大语言模型表征空间的更多潜力,为AI模型的解释性和可控性提供新的思路。
ReFT的提出不仅为大语言模型的微调提供了更高效的解决方案,也为AI领域的研究开辟了新的方向。随着技术的不断演进,ReFT有望在更多实际场景中发挥重要作用,推动人工智能的进一步发展。





